CNN Technical Breakdown: EfficientNetB0
Table of Content
Block
Introduction
EfficientNet is a family of Convolutional Neural Network (CNN) that were introduced in EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks - Tan & Le 2019. Their paper focus on their novel scaling method, which scales all 3 conventional dimension of a CNN: depth, width, and resolution. With this scaling method, their already powerful baseline EfficientNetB0 that achieves ~75% top-1 accuracy on ImageNet with less than 5M parameters, scaled to EfficientNetB7 which achieved state-of-the-art performance (SOTA) on multiple public datasets.
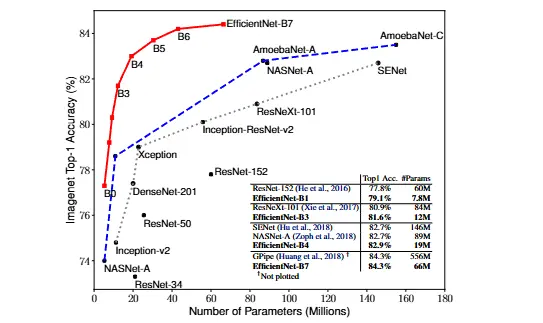
EfficientNetB0
In this post, we will focus on the baseline model EfficientNetB0, tackling its architecture, technical details and less about the scaling paradigm introduced in the paper. The basis for EfficientNetB0 architecture were formulated using neural architecture search.
There are very little technical details about EfficientNetB0 in the original paper, so we are going to have to explore from what we have.
Architecture
| Stage $i$ | Operator $\hat{F}_i$ | Resolution $\hat{H}_i \times \hat{W}_i$ | #Channels $\hat{C}_i$ | #Layers $\hat{L}_i$ |
|---|---|---|---|---|
| 1 | Conv3x3 | $224 \times 224$ | 32 | 1 |
| 2 | MBConv1, k3x3 | $112 \times 112$ | 16 | 1 |
| 3 | MBConv6, k3x3 | $112 \times 112$ | 24 | 2 |
| 4 | MBConv6, k5x5 | $56 \times 56$ | 40 | 2 |
| 5 | MBConv6, k3x3 | $28 \times 28$ | 80 | 3 |
| 6 | MBConv6, k5x5 | $14 \times 14$ | 112 | 3 |
| 7 | MBConv6, k5x5 | $14 \times 14$ | 192 | 4 |
| 8 | MBConv6, k3x3 | $7 \times 7$ | 320 | 1 |
| 9 | Conv1x1 & Pooling & FC | $7 \times 7$ | 1280 | 1 |
Block“Its main building block is mobile inverted bottleneck MBConv (Sandler et al., 2018; Tan et al., 2019), to which we also add squeeze-and-excitation optimization (Hu et al., 2018).” - Tan & Le., 2019
We will be focusing most on the above section from the paper, as most of what we can make of the architecture of EfficientNetB0 is here. Below is a very brief recap of the 3 papers cited in the quote above:
- MobileNetV2: Inverted Residuals and Linear Bottlenecks (Sandler et al., 2018): This paper introduces the MobileNetV2 architecture, which features the mobile inverted bottleneck MBConv block. This block is a fundamental building block of EfficientNet-B0. The inverted residual block connects low-dimensional bottleneck layers with shortcuts and expands to a higher dimension using a depthwise convolution, then projects back to a bottleneck with a linear layer.
- MnasNet: Platform-Aware Neural Architecture Search for Mobile (Tan et al., 2019): This paper proposes an automated neural architecture search (NAS) approach to design efficient CNN models for mobile devices. Crucially, the neural architecture search space used to develop the baseline EfficientNet-B0 was the same as that explored in MnasNet.
- Squeeze-and-Excitation Networks (Hu et al., 2018): This paper introduces the Squeeze-and-Excitation (SE) block, an architectural unit designed to improve a network’s representational power through adaptive channel-wise feature recalibration. The SE block consists of a squeeze operation (typically global average pooling) to gather global spatial information into channel descriptors, and an excitation operation which uses a gating mechanism with a sigmoid activation to model channel dependencies. EfficientNet-B0 incorporates this squeeze-and-excitation optimization into its MBConv blocks, and the Squeeze-and-excitation ratio was an architectural choice included in the MnasNet search space that was also used for EfficientNet-B0.
print(model) output of EfficientNetB0 is at the end of this post. Also during my testing I obtained a image detailing the entire architecture of EfficientNetB0, for now its quite inconvenient to get that picture on here so if you want that just contact me through the channels in the footer. Nevertheless, I OCRed that image, then fed the text into Gemini 2.5 Flash and got a detailed breakdown that seems accurate to the architecture in the paper, also at the end of this post.
Building Blocks
Point-wise Convolution
A 1x1 point-wise conv. essentially are just normal Conv2D layers with 1x1 “kernels”.
In traditional CNNs, you would usually use kernels of bigger sizes like 3x3, 5x5,… Say, if you have an image of shape (H, W, C) with C being the number of channel, and you convolve it with n kernels of shape (k, k), what you’d get is an activation tensor of shape (H - k - 1, W - k - 1, n). As you can see, these kernels are doing quite the heavy lifting, having to capture both spatial information (across (H, W)) and also cross-channel characteristic (across C). The solution? Using 1x1 kernels allow you to only focus on the channels, essentially breaking down 1/2 of the task that traditional Conv2D had to handle.
A nice way to visualize these is to think of an image of shape (H, W, C_in). Now, if we use a 1x1 kernel (this kernel will be of shape (1, 1, C_in)) to convolve with this image, then at pixel (x, y), there will be a “vector” of input of shape (1, 1, C_in), and when the kernel get to this pixel, it will essentially be like a linear layer, similar to a “logit” in logistic regression, without any non-linearity.
These layers will give us cross-channel interaction, and for the spatial information? That’s what the next section will tell you.
Depth-wise Convolution
Depth-wise convolution is actually really similar to Conv2D, and the kernel sizes are also similar, usually 3x3, 5x5,… But to understand their differences, lets go back to the example in the last section:
BlockIn traditional CNNs, you would usually use kernels of bigger sizes like 3x3, 5x5,… Say, if you have an image of shape
(H, W, C)withCbeing the number of channel, and you convolve it withnkernels of shape(k, k), what you’d get is an activation tensor of shape(H - k - 1, W - k - 1, n). As you can see, these kernels are doing quite the heavy lifting, having to capture both spatial information (across(H, W)) and also cross-channel characteristic (acrossC). The solution? Using 1x1 kernels allow you to only focus on the channels, essentially breaking down 1/2 of the task that traditionalConv2Dhad to handle.
Depth-wise convolution essentially handles that other half. For an image of shape (H, W, C), the number of depth-wise kernels would usually be C x ext_fac with ext_fac being an expansion factor, thus, each channel will get their own separate ext_fac number of kernels, and these kernels are only used for those channels, so not a “full” convolution in the traditional Conv2D manner. That is exactly how we handle the spatial information while not complicating the kernels with cross-channel info.
As you can see, both point-wise and depth-wise work together to still achieve the desired intuition of Conv2D, while significantly reducing the number of parameters and being more efficient and stable at training.
Inverted Residual
Inverted here doesn’t mean backwards, as introduced in Sandler et al., 2018, their main characteristic is using residual to go from a “narrow” layer, skipping a “wide” layer, to connect to another “narrow” layer. In older architectures like ResNet, where they first introduced residual connections in CNNs, it was usually to go from a “wide” to “narrow” to “wide” representation, this is what Inverted mean in question.
So its not really anything that special, its still additive, and serving similar purpose as residual connections should be.
SE Optimization
In a nut shell this is a form of “attention” for CNNs. Traditional CNNs usually treat all feature channels equally, so this SE optimization technique allows them to dynamically and explicitly learn which channel is actually important.
Specifically, the squeeze part squishes the representation, and then it tries to predict a set of importance weight for each channels. Those weights then rescales (excite) the channels, allowing more important channels to dominate.
Appendix
Gemini 2.5 Flash Breakdown
This neural network processes input data through a series of layers, progressively transforming the data to extract features and ultimately make a prediction. The architecture begins with input handling and proceeds through multiple blocks, each comprising various convolutional, normalization, activation, and attention mechanisms.
Input and Initial Processing Layers
-
input_layer (InputLayer): Receives the initial data.
- Input shape:
(None, 224, 224, 3) - Output shape:
(None, 224, 224, 3)
- Input shape:
-
rescaling (Rescaling): Adjusts the scale of input data.
- Input shape:
(None, 224, 224, 3) - Output shape:
(None, 224, 224, 3)
- Input shape:
-
normalization (Normalization): Normalizes the input data.
- Input shape:
(None, 224, 224, 3) - Output shape:
(None, 224, 224, 3)
- Input shape:
-
rescaling_1 (Rescaling): Another rescaling operation.
- Input shape:
(None, 224, 224, 3) - Output shape:
(None, 224, 224, 3)
- Input shape:
Stem Block
The initial convolutional stem processes the pre-processed input.
-
stem_conv_pad (ZeroPadding2D): Adds padding to the input for convolutional operations.
- Input shape:
(None, 224, 224, 3) - Output shape:
(None, 225, 225, 3)
- Input shape:
-
stem_conv (Conv2D): Applies a 2D convolutional filter.
- Input shape:
(None, 225, 225, 3) - Output shape:
(None, 112, 112, 32)
- Input shape:
-
stem_bn (BatchNormalization): Normalizes the activations of the previous layer.
- Input shape:
(None, 112, 112, 32) - Output shape:
(None, 112, 112, 32)
- Input shape:
-
stem_activation (Activation): Applies an activation function to the normalized output.
- Input shape:
(None, 112, 112, 32) - Output shape:
(None, 112, 112, 32)
- Input shape:
Block 1a
This block introduces depthwise separable convolutions and a Squeeze-and-Excitation (SE) block.
-
block1a_dwconv (DepthwiseConv2D): Performs a depthwise 2D convolution.
- Input shape:
(None, 112, 112, 32) - Output shape:
(None, 112, 112, 32)
- Input shape:
-
block1a_bn (BatchNormalization): Normalizes the depthwise convolution output.
- Input shape:
(None, 112, 112, 32) - Output shape:
(None, 112, 112, 32)
- Input shape:
-
block1a_activation (Activation): Applies an activation function.
- Input shape:
(None, 112, 112, 32) - Output shape:
(None, 112, 112, 32)
- Input shape:
-
block1a_se_squeeze (GlobalAveragePooling2D): Global average pooling for the SE block.
- Input shape:
(None, 112, 112, 32) - Output shape:
(None, 32)
- Input shape:
-
block1a_se_reshape (Reshape): Reshapes the pooled output.
- Input shape:
(None, 32) - Output shape:
(None, 1, 1, 32)
- Input shape:
-
block1a_se_reduce (Conv2D): Reduces channels in the SE block.
- Input shape:
(None, 1, 1, 32) - Output shape:
(None, 1, 1, 8)
- Input shape:
-
block1a_se_expand (Conv2D): Expands channels in the SE block.
- Input shape:
(None, 1, 1, 8) - Output shape:
(None, 1, 1, 32)
- Input shape:
-
block1a_se_excite (Multiply): Multiplies the original feature map with the SE block output.
- Input shape:
[(None, 112, 112, 32), (None, 1, 1, 32)] - Output shape:
(None, 112, 112, 32)
- Input shape:
-
block1a_project_conv (Conv2D): Projects the features to a new channel dimension.
- Input shape:
(None, 112, 112, 32) - Output shape:
(None, 112, 112, 16)
- Input shape:
-
block1a_project_bn (BatchNormalization): Normalizes the projected features.
- Input shape:
(None, 112, 112, 16) - Output shape:
(None, 112, 112, 16)
- Input shape:
Block 2a
This block follows a similar structure to Block 1a, with an expansion, depthwise convolution (with padding), and SE block.
-
block2a_expand_conv (Conv2D): Expands the number of channels.
- Input shape:
(None, 112, 112, 16) - Output shape:
(None, 112, 112, 96)
- Input shape:
-
block2a_expand_bn (BatchNormalization): Normalizes expanded features.
- Input shape:
(None, 112, 112, 96) - Output shape:
(None, 112, 112, 96)
- Input shape:
-
block2a_expand_activation (Activation): Activates expanded features.
- Input shape:
(None, 112, 112, 96) - Output shape:
(None, 112, 112, 96)
- Input shape:
-
block2a_dwconv_pad (ZeroPadding2D): Pads for depthwise convolution.
- Input shape:
(None, 112, 112, 96) - Output shape:
(None, 113, 113, 96)
- Input shape:
-
block2a_dv (DepthwiseConv2D): Performs depthwise convolution.
- Input shape:
(None, 113, 113, 96) - Output shape:
(None, 56, 56, 96)
- Input shape:
-
block2a_bn (BatchNormalization): Normalizes depthwise convolution output.
- Input shape:
(None, 56, 56, 96) - Output shape:
(None, 56, 56, 96)
- Input shape:
-
block2a_activation (Activation): Activates depthwise convolution output.
- Input shape:
(None, 56, 56, 96) - Output shape:
(None, 56, 56, 96)
- Input shape:
-
block2a_se_squeeze (GlobalAveragePooling2D): Global average pooling for SE.
- Input shape:
(None, 56, 56, 96) - Output shape:
(None, 96)
- Input shape:
-
block2a_se_reshape (Reshape): Reshapes for SE.
- Input shape:
(None, 96) - Output shape:
(None, 1, 1, 96)
- Input shape:
-
block2a_se_reduce (Conv2D): Reduces channels in SE.
- Input shape:
(None, 1, 1, 96) - Output shape:
(None, 1, 1, 4)
- Input shape:
-
block2a_se_expand (Conv2D): Expands channels in SE.
- Input shape:
(None, 1, 1, 4) - Output shape:
(None, 1, 1, 96)
- Input shape:
-
block2a_se_excite (Multiply): Multiplies with SE output.
- Input shape:
[(None, 56, 56, 96), (None, 1, 1, 96)] - Output shape:
(None, 56, 56, 96)
- Input shape:
-
block2a_project_conv (Conv2D): Projects features.
- Input shape:
(None, 56, 56, 96) - Output shape:
(None, 56, 56, 24)
- Input shape:
-
block2a_project_bn (BatchNormalization): Normalizes projected features.
- Input shape:
(None, 56, 56, 24) - Output shape:
(None, 56, 56, 24)
- Input shape:
Block 2b
This block continues the pattern of expansion, depthwise convolution, SE block, and projection, and introduces a dropout layer and an additive skip connection.
-
block2b_expand_conv (Conv2D): Expands channels.
- Input shape:
(None, 56, 56, 24) - Output shape:
(None, 56, 56, 144)
- Input shape:
-
block2b_expand_bn (BatchNormalization): Normalizes expanded features.
- Input shape:
(None, 56, 56, 144) - Output shape:
(None, 56, 56, 144)
- Input shape:
-
block2b_expand_activation (Activation): Activates expanded features.
- Input shape:
(None, 56, 56, 144) - Output shape:
(None, 56, 56, 144)
- Input shape:
-
block2b_dwconv (DepthwiseConv2D): Performs depthwise convolution.
- Input shape:
(None, 56, 56, 144) - Output shape:
(None, 56, 56, 144)
- Input shape:
-
block2b_bn (BatchNormalization): Normalizes depthwise convolution output.
- Input shape:
(None, 56, 56, 144) - Output shape:
(None, 56, 56, 144)
- Input shape:
-
block2b_activation (Activation): Activates depthwise convolution output.
- Input shape:
(None, 56, 56, 144) - Output shape:
(None, 56, 56, 144)
- Input shape:
-
block2b_se_squeeze (GlobalAveragePooling2D): Global average pooling for SE.
- Input shape:
(None, 56, 56, 144) - Output shape:
(None, 144)
- Input shape:
-
block2b_se_reshape (Reshape): Reshapes for SE.
- Input shape:
(None, 144) - Output shape:
(None, 1, 1, 144)
- Input shape:
-
block2b_se_reduce (Conv2D): Reduces channels in SE.
- Input shape:
(None, 1, 1, 144) - Output shape:
(None, 1, 1, 6)
- Input shape:
-
block2b_se_expand (Conv2D): Expands channels in SE.
- Input shape:
(None, 1, 1, 6) - Output shape:
(None, 1, 1, 144)
- Input shape:
-
block2b_se_excite (Multiply): Multiplies with SE output.
- Input shape:
[(None, 56, 56, 144), (None, 1, 1, 144)] - Output shape:
(None, 56, 56, 144)
- Input shape:
-
block2b_project_conv (Conv2D): Projects features.
- Input shape:
(None, 56, 56, 144) - Output shape:
(None, 56, 56, 24)
- Input shape:
-
block2b_project_bn (BatchNormalization): Normalizes projected features.
- Input shape:
(None, 56, 56, 24) - Output shape:
(None, 56, 56, 24)
- Input shape:
-
block2b_drop (Dropout): Applies dropout for regularization.
- Input shape:
(None, 56, 56, 24) - Output shape:
(None, 56, 56, 24)
- Input shape:
-
block2b_add (Add): Adds the input of the block to its output (skip connection).
- Input shape:
[(None, 56, 56, 24), (None, 56, 56, 24)] - Output shape:
(None, 56, 56, 24)
- Input shape:
Block 3a
Similar to previous blocks, with padding for a downsampling depthwise convolution.
-
block3a_expand_conv (Conv2D): Expands channels.
- Input shape:
(None, 56, 56, 24) - Output shape:
(None, 56, 56, 144)
- Input shape:
-
block3a_expand_bn (BatchNormalization): Normalizes expanded features.
- Input shape:
(None, 56, 56, 144) - Output shape:
(None, 56, 56, 144)
- Input shape:
-
block3a_expand_activation (Activation): Activates expanded features.
- Input shape:
(None, 56, 56, 144) - Output shape:
(None, 56, 56, 144)
- Input shape:
-
block3a_dwconv_pad (ZeroPadding2D): Pads for depthwise convolution.
- Input shape:
(None, 56, 56, 144) - Output shape:
(None, 59, 59, 144)
- Input shape:
-
block3a_dwconv (DepthwiseConv2D): Performs depthwise convolution.
- Input shape:
(None, 59, 59, 144) - Output shape:
(None, 28, 28, 144)
- Input shape:
-
block3a_bn (BatchNormalization): Normalizes depthwise convolution output.
- Input shape:
(None, 28, 28, 144) - Output shape:
(None, 28, 28, 144)
- Input shape:
-
block3a_activation (Activation): Activates depthwise convolution output.
- Input shape:
(None, 28, 28, 144) - Output shape:
(None, 28, 28, 144)
- Input shape:
-
block3a_se_squeeze (GlobalAveragePooling2D): Global average pooling for SE.
- Input shape:
(None, 28, 28, 144) - Output shape:
(None, 144)
- Input shape:
-
block3a_se_reshape (Reshape): Reshapes for SE.
- Input shape:
(None, 144) - Output shape:
(None, 1, 1, 144)
- Input shape:
-
block3a_se_reduce (Conv2D): Reduces channels in SE.
- Input shape:
(None, 1, 1, 144) - Output shape:
(None, 1, 1, 6)
- Input shape:
-
block3a_se_expand (Conv2D): Expands channels in SE.
- Input shape:
(None, 1, 1, 6) - Output shape:
(None, 1, 1, 144)
- Input shape:
-
block3a_se_excite (Multiply): Multiplies with SE output.
- Input shape:
[(None, 28, 28, 144), (None, 1, 1, 144)] - Output shape:
(None, 28, 28, 144)
- Input shape:
-
block3a_project_conv (Conv2D): Projects features.
- Input shape:
(None, 28, 28, 144) - Output shape:
(None, 28, 28, 40)
- Input shape:
-
block3a_project_bn (BatchNormalization): Normalizes projected features.
- Input shape:
(None, 28, 28, 40) - Output shape:
(None, 28, 28, 40)
- Input shape:
Block 3b
This block continues the pattern of expansion, depthwise convolution, SE block, projection, dropout, and additive skip connection.
-
block3b_expand_conv (Conv2D): Expands channels.
- Input shape:
(None, 28, 28, 40) - Output shape:
(None, 28, 28, 240)
- Input shape:
-
block3b_expand_bn (BatchNormalization): Normalizes expanded features.
- Input shape:
(None, 28, 28, 240) - Output shape:
(None, 28, 28, 240)
- Input shape:
-
block3b_expand_activation (Activation): Activates expanded features.
- Input shape:
(None, 28, 28, 240) - Output shape:
(None, 28, 28, 240)
- Input shape:
-
block3b_dwconv (DepthwiseConv2D): Performs depthwise convolution.
- Input shape:
(None, 28, 28, 240) - Output shape:
(None, 28, 28, 240)
- Input shape:
-
block3b_bn (BatchNormalization): Normalizes depthwise convolution output.
- Input shape:
(None, 28, 28, 240) - Output shape:
(None, 28, 28, 240)
- Input shape:
-
block3b_activation (Activation): Activates depthwise convolution output.
- Input shape:
(None, 28, 28, 240) - Output shape:
(None, 28, 28, 240)
- Input shape:
-
block3b_se_squeeze (GlobalAveragePooling2D): Global average pooling for SE.
- Input shape:
(None, 28, 28, 240) - Output shape:
(None, 240)
- Input shape:
-
block3b_se_reshape (Reshape): Reshapes for SE.
- Input shape:
(None, 240) - Output shape:
(None, 1, 1, 240)
- Input shape:
-
block3b_se_reduce (Conv2D): Reduces channels in SE.
- Input shape:
(None, 1, 1, 240) - Output shape:
(None, 1, 1, 10)
- Input shape:
-
block3b_se_expand (Conv2D): Expands channels in SE.
- Input shape:
(None, 1, 1, 10) - Output shape:
(None, 1, 1, 240)
- Input shape:
-
block3b_se_excite (Multiply): Multiplies with SE output.
- Input shape:
[(None, 28, 28, 240), (None, 1, 1, 240)] - Output shape:
(None, 28, 28, 240)
- Input shape:
-
block3b_project_conv (Conv2D): Projects features.
- Input shape:
(None, 28, 28, 240) - Output shape:
(None, 28, 28, 40)
- Input shape:
-
block3b_project_bn (BatchNormalization): Normalizes projected features.
- Input shape:
(None, 28, 28, 40) - Output shape:
(None, 28, 28, 40)
- Input shape:
-
block3b_drop (Dropout): Applies dropout.
- Input shape:
(None, 28, 28, 40) - Output shape:
(None, 28, 28, 40)
- Input shape:
-
block3b_add (Add): Adds the input of the block to its output (skip connection).
- Input shape:
[(None, 28, 28, 40), (None, 28, 28, 40)] - Output shape:
(None, 28, 28, 40)
- Input shape:
Block 4a
Another block with expansion, padded depthwise convolution for downsampling, and an SE block.
-
block4a_expand_conv (Conv2D): Expands channels.
- Input shape:
(None, 28, 28, 40) - Output shape:
(None, 28, 28, 240)
- Input shape:
-
block4a_expand_bn (BatchNormalization): Normalizes expanded features.
- Input shape:
(None, 28, 28, 240) - Output shape:
(None, 28, 28, 240)
- Input shape:
-
block4a_expand_activation (Activation): Activates expanded features.
- Input shape:
(None, 28, 28, 240) - Output shape:
(None, 28, 28, 240)
- Input shape:
-
block4a_dwconv_pad (ZeroPadding2D): Pads for depthwise convolution.
- Input shape:
(None, 28, 28, 240) - Output shape:
(None, 29, 29, 240)
- Input shape:
-
block4a_dwconv (DepthwiseConv2D): Performs depthwise convolution.
- Input shape:
(None, 29, 29, 240) - Output shape:
(None, 14, 14, 240)
- Input shape:
-
block4a_bn (BatchNormalization): Normalizes depthwise convolution output.
- Input shape:
(None, 14, 14, 240) - Output shape:
(None, 14, 14, 240)
- Input shape:
-
block4a_activation (Activation): Activates depthwise convolution output.
- Input shape:
(None, 14, 14, 240) - Output shape:
(None, 14, 14, 240)
- Input shape:
-
block4a_se_squeeze (GlobalAveragePooling2D): Global average pooling for SE.
- Input shape:
(None, 14, 14, 240) - Output shape:
(None, 240)
- Input shape:
-
block4a_se_reshape (Reshape): Reshapes for SE.
- Input shape:
(None, 240) - Output shape:
(None, 1, 1, 240)
- Input shape:
-
block4a_se_reduce (Conv2D): Reduces channels in SE.
- Input shape:
(None, 1, 1, 240) - Output shape:
(None, 1, 1, 10)
- Input shape:
-
block4a_se_expand (Conv2D): Expands channels in SE.
- Input shape:
(None, 1, 1, 10) - Output shape:
(None, 1, 1, 240)
- Input shape:
-
block4a_se_excite (Multiply): Multiplies with SE output.
- Input shape:
[(None, 14, 14, 240), (None, 1, 1, 240)] - Output shape:
(None, 14, 14, 240)
- Input shape:
-
block4a_project_conv (Conv2D): Projects features.
- Input shape:
(None, 14, 14, 240) - Output shape:
(None, 14, 14, 80)
- Input shape:
-
block4a_project_bn (BatchNormalization): Normalizes projected features.
- Input shape:
(None, 14, 14, 80) - Output shape:
(None, 14, 14, 80)
- Input shape:
Block 4b
This block includes expansion, depthwise convolution, SE block, projection, dropout, and an additive skip connection.
-
block4b_expand_conv (Conv2D): Expands channels.
- Input shape:
(None, 14, 14, 80) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block4b_expand_bn (BatchNormalization): Normalizes expanded features.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block4b_expand_activation (Activation): Activates expanded features.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block4b_dwconv (DepthwiseConv2D): Performs depthwise convolution.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block4b_bn (BatchNormalization): Normalizes depthwise convolution output.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block4b_activation (Activation): Activates depthwise convolution output.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block4b_se_squeeze (GlobalAveragePooling2D): Global average pooling for SE.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 480)
- Input shape:
-
block4b_se_reshape (Reshape): Reshapes for SE.
- Input shape:
(None, 480) - Output shape:
(None, 1, 1, 480)
- Input shape:
-
block4b_se_reduce (Conv2D): Reduces channels in SE.
- Input shape:
(None, 1, 1, 480) - Output shape:
(None, 1, 1, 20)
- Input shape:
-
block4b_se_expand (Conv2D): Expands channels in SE.
- Input shape:
(None, 1, 1, 20) - Output shape:
(None, 1, 1, 480)
- Input shape:
-
block4b_se_excite (Multiply): Multiplies with SE output.
- Input shape:
[(None, 14, 14, 480), (None, 1, 1, 480)] - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block4b_project_conv (Conv2D): Projects features.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 80)
- Input shape:
-
block4b_project_bn (BatchNormalization): Normalizes projected features.
- Input shape:
(None, 14, 14, 80) - Output shape:
(None, 14, 14, 80)
- Input shape:
-
block4b_drop (Dropout): Applies dropout.
- Input shape:
(None, 14, 14, 80) - Output shape:
(None, 14, 14, 80)
- Input shape:
-
block4b_add (Add): Adds the input of the block to its output (skip connection).
- Input shape:
[(None, 14, 14, 80), (None, 14, 14, 80)] - Output shape:
(None, 14, 14, 80)
- Input shape:
Block 4c
This block continues the pattern of expansion, depthwise convolution, SE block, projection, dropout, and an additive skip connection.
-
block4c_expand_conv (Conv2D): Expands channels.
- Input shape:
(None, 14, 14, 80) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block4c_expand_bn (BatchNormalization): Normalizes expanded features.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block4c_expand_activation (Activation): Activates expanded features.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block4c_dwconv (DepthwiseConv2D): Performs depthwise convolution.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block4c_bn (BatchNormalization): Normalizes depthwise convolution output.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block4c_activation (Activation): Activates depthwise convolution output.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block4c_se_squeeze (GlobalAveragePooling2D): Global average pooling for SE.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 480)
- Input shape:
-
block4c_se_reshape (Reshape): Reshapes for SE.
- Input shape:
(None, 480) - Output shape:
(None, 1, 1, 480)
- Input shape:
-
block4c_se_reduce (Conv2D): Reduces channels in SE.
- Input shape:
(None, 1, 1, 480) - Output shape:
(None, 1, 1, 20)
- Input shape:
-
block4c_se_expand (Conv2D): Expands channels in SE.
- Input shape:
(None, 1, 1, 20) - Output shape:
(None, 1, 1, 480)
- Input shape:
-
block4c_se_excite (Multiply): Multiplies with SE output.
- Input shape:
[(None, 14, 14, 480), (None, 1, 1, 480)] - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block4c_project_conv (Conv2D): Projects features.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 80)
- Input shape:
-
block4c_project_bn (BatchNormalization): Normalizes projected features.
- Input shape:
(None, 14, 14, 80) - Output shape:
(None, 14, 14, 80)
- Input shape:
-
block4c_drop (Dropout): Applies dropout.
- Input shape:
(None, 14, 14, 80) - Output shape:
(None, 14, 14, 80)
- Input shape:
-
block4c_add (Add): Adds the input of the block to its output (skip connection).
- Input shape:
[(None, 14, 14, 80), (None, 14, 14, 80)] - Output shape:
(None, 14, 14, 80)
- Input shape:
Block 5a
This block follows the pattern of expansion, depthwise convolution, and SE block.
-
block5a_expand_conv (Conv2D): Expands channels.
- Input shape:
(None, 14, 14, 80) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block5a_expand_bn (BatchNormalization): Normalizes expanded features.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block5a_expand_activation (Activation): Activates expanded features.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block5a_dwconv (DepthwiseConv2D): Performs depthwise convolution.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block5a_bn (BatchNormalization): Normalizes depthwise convolution output.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block5a_activation (Activation): Activates depthwise convolution output.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block5a_se_squeeze (GlobalAveragePooling2D): Global average pooling for SE.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 480)
- Input shape:
-
block5a_se_reshape (Reshape): Reshapes for SE.
- Input shape:
(None, 480) - Output shape:
(None, 1, 1, 480)
- Input shape:
-
block5a_se_reduce (Conv2D): Reduces channels in SE.
- Input shape:
(None, 1, 1, 480) - Output shape:
(None, 1, 1, 20)
- Input shape:
-
block5a_se_expand (Conv2D): Expands channels in SE.
- Input shape:
(None, 1, 1, 20) - Output shape:
(None, 1, 1, 480)
- Input shape:
-
block5a_se_excite (Multiply): Multiplies with SE output.
- Input shape:
[(None, 14, 14, 480), (None, 1, 1, 480)] - Output shape:
(None, 14, 14, 480)
- Input shape:
-
block5a_project_conv (Conv2D): Projects features.
- Input shape:
(None, 14, 14, 480) - Output shape:
(None, 14, 14, 112)
- Input shape:
-
block5a_project_bn (BatchNormalization): Normalizes projected features.
- Input shape:
(None, 14, 14, 112) - Output shape:
(None, 14, 14, 112)
- Input shape:
Block 5b
This block includes expansion, depthwise convolution, SE block, projection, dropout, and an additive skip connection.
-
block5b_expand_conv (Conv2D): Expands channels.
- Input shape:
(None, 14, 14, 112) - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block5b_expand_bn (BatchNormalization): Normalizes expanded features.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block5b_expand_activation (Activation): Activates expanded features.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block5b_dwconv (DepthwiseConv2D): Performs depthwise convolution.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block5b_bn (BatchNormalization): Normalizes depthwise convolution output.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block5b_activation (Activation): Activates depthwise convolution output.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block5b_se_squeeze (GlobalAveragePooling2D): Global average pooling for SE.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 672)
- Input shape:
-
block5b_se_reshape (Reshape): Reshapes for SE.
- Input shape:
(None, 672) - Output shape:
(None, 1, 1, 672)
- Input shape:
-
block5b_se_reduce (Conv2D): Reduces channels in SE.
- Input shape:
(None, 1, 1, 672) - Output shape:
(None, 1, 1, 28)
- Input shape:
-
block5b_se_expand (Conv2D): Expands channels in SE.
- Input shape:
(None, 1, 1, 28) - Output shape:
(None, 1, 1, 672)
- Input shape:
-
block5b_se_excite (Multiply): Multiplies with SE output.
- Input shape:
[(None, 14, 14, 672), (None, 1, 1, 672)] - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block5b_project_conv (Conv2D): Projects features.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 14, 14, 112)
- Input shape:
-
block5b_project_bn (BatchNormalization): Normalizes projected features.
- Input shape:
(None, 14, 14, 112) - Output shape:
(None, 14, 14, 112)
- Input shape:
-
block5b_drop (Dropout): Applies dropout.
- Input shape:
(None, 14, 14, 112) - Output shape:
(None, 14, 14, 112)
- Input shape:
-
block5b_add (Add): Adds the input of the block to its output (skip connection).
- Input shape:
[(None, 14, 14, 112), (None, 14, 14, 112)] - Output shape:
(None, 14, 14, 112)
- Input shape:
Block 5c
This block continues the pattern of expansion, depthwise convolution, SE block, projection, dropout, and an additive skip connection.
-
block5c_expand_conv (Conv2D): Expands channels.
- Input shape:
(None, 14, 14, 112) - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block5c_expand_bn (BatchNormalization): Normalizes expanded features.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block5c_expand_activation (Activation): Activates expanded features.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block5c_dwconv (DepthwiseConv2D): Performs depthwise convolution.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block5c_bn (BatchNormalization): Normalizes depthwise convolution output.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block5c_activation (Activation): Activates depthwise convolution output.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block5c_se_squeeze (GlobalAveragePooling2D): Global average pooling for SE.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 672)
- Input shape:
-
block5c_se_reshape (Reshape): Reshapes for SE.
- Input shape:
(None, 672) - Output shape:
(None, 1, 1, 672)
- Input shape:
-
block5c_se_reduce (Conv2D): Reduces channels in SE.
- Input shape:
(None, 1, 1, 672) - Output shape:
(None, 1, 1, 28)
- Input shape:
-
block5c_se_expand (Conv2D): Expands channels in SE.
- Input shape:
(None, 1, 1, 28) - Output shape:
(None, 1, 1, 672)
- Input shape:
-
block5c_se_excite (Multiply): Multiplies with SE output.
- Input shape:
[(None, 14, 14, 672), (None, 1, 1, 672)] - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block5c_project_conv (Conv2D): Projects features.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 14, 14, 112)
- Input shape:
-
block5c_project_bn (BatchNormalization): Normalizes projected features.
- Input shape:
(None, 14, 14, 112) - Output shape:
(None, 14, 14, 112)
- Input shape:
-
block5c_drop (Dropout): Applies dropout.
- Input shape:
(None, 14, 14, 112) - Output shape:
(None, 14, 14, 112)
- Input shape:
-
block5c_add (Add): Adds the input of the block to its output (skip connection).
- Input shape:
[(None, 14, 14, 112), (None, 14, 14, 112)] - Output shape:
(None, 14, 14, 112)
- Input shape:
Block 6a
This block includes expansion, padded depthwise convolution for downsampling, and an SE block.
-
block6a_expand_conv (Conv2D): Expands channels.
- Input shape:
(None, 14, 14, 112) - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block6a_expand_bn (BatchNormalization): Normalizes expanded features.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block6a_expand_activation (Activation): Activates expanded features.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 14, 14, 672)
- Input shape:
-
block6a_dwconv_pad (ZeroPadding2D): Pads for depthwise convolution.
- Input shape:
(None, 14, 14, 672) - Output shape:
(None, 17, 17, 672)
- Input shape:
-
block6a_dwconv (DepthwiseConv2D): Performs depthwise convolution.
- Input shape:
(None, 17, 17, 672) - Output shape:
(None, 7, 7, 672)
- Input shape:
-
block6a_bn (BatchNormalization): Normalizes depthwise convolution output.
- Input shape:
(None, 7, 7, 672) - Output shape:
(None, 7, 7, 672)
- Input shape:
-
block6a_activation (Activation): Activates depthwise convolution output.
- Input shape:
(None, 7, 7, 672) - Output shape:
(None, 7, 7, 672)
- Input shape:
-
block6a_se_squeeze (GlobalAveragePooling2D): Global average pooling for SE.
- Input shape:
(None, 7, 7, 672) - Output shape:
(None, 672)
- Input shape:
-
block6a_se_reshape (Reshape): Reshapes for SE.
- Input shape:
(None, 672) - Output shape:
(None, 1, 1, 672)
- Input shape:
-
block6a_se_reduce (Conv2D): Reduces channels in SE.
- Input shape:
(None, 1, 1, 672) - Output shape:
(None, 1, 1, 28)
- Input shape:
-
block6a_se_expand (Conv2D): Expands channels in SE.
- Input shape:
(None, 1, 1, 28) - Output shape:
(None, 1, 1, 672)
- Input shape:
-
block6a_se_excite (Multiply): Multiplies with SE output.
- Input shape:
[(None, 7, 7, 672), (None, 1, 1, 672)] - Output shape:
(None, 7, 7, 672)
- Input shape:
-
block6a_project_conv (Conv2D): Projects features.
- Input shape:
(None, 7, 7, 672) - Output shape:
(None, 7, 7, 192)
- Input shape:
-
block6a_project_bn (BatchNormalization): Normalizes projected features.
- Input shape:
(None, 7, 7, 192) - Output shape:
(None, 7, 7, 192)
- Input shape:
Block 6b
This block includes expansion, depthwise convolution, SE block, projection, dropout, and an additive skip connection.
-
block6b_expand_conv (Conv2D): Expands channels.
- Input shape:
(None, 7, 7, 192) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6b_expand_bn (BatchNormalization): Normalizes expanded features.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6b_expand_activation (Activation): Activates expanded features.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6b_dwconv (DepthwiseConv2D): Performs depthwise convolution.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6b_bn (BatchNormalization): Normalizes depthwise convolution output.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6b_activation (Activation): Activates depthwise convolution output.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6b_se_squeeze (GlobalAveragePooling2D): Global average pooling for SE.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 1152)
- Input shape:
-
block6b_se_reshape (Reshape): Reshapes for SE.
- Input shape:
(None, 1152) - Output shape:
(None, 1, 1, 1152)
- Input shape:
-
block6b_se_reduce (Conv2D): Reduces channels in SE.
- Input shape:
(None, 1, 1, 1152) - Output shape:
(None, 1, 1, 48)
- Input shape:
-
block6b_se_expand (Conv2D): Expands channels in SE.
- Input shape:
(None, 1, 1, 48) - Output shape:
(None, 1, 1, 1152)
- Input shape:
-
block6b_se_excite (Multiply): Multiplies with SE output.
- Input shape:
[(None, 7, 7, 1152), (None, 1, 1, 1152)] - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6b_project_conv (Conv2D): Projects features.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 192)
- Input shape:
-
block6b_project_bn (BatchNormalization): Normalizes projected features.
- Input shape:
(None, 7, 7, 192) - Output shape:
(None, 7, 7, 192)
- Input shape:
-
block6b_drop (Dropout): Applies dropout.
- Input shape:
(None, 7, 7, 192) - Output shape:
(None, 7, 7, 192)
- Input shape:
-
block6b_add (Add): Adds the input of the block to its output (skip connection).
- Input shape:
[(None, 7, 7, 192), (None, 7, 7, 192)] - Output shape:
(None, 7, 7, 192)
- Input shape:
Block 6c
This block continues the pattern of expansion, depthwise convolution, SE block, projection, dropout, and an additive skip connection.
-
block6c_expand_conv (Conv2D): Expands channels.
- Input shape:
(None, 7, 7, 192) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6c_expand_bn (BatchNormalization): Normalizes expanded features.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6c_expand_activation (Activation): Activates expanded features.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6c_dwconv (DepthwiseConv2D): Performs depthwise convolution.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6c_bn (BatchNormalization): Normalizes depthwise convolution output.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6c_activation (Activation): Activates depthwise convolution output.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6c_se_squeeze (GlobalAveragePooling2D): Global average pooling for SE.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 1152)
- Input shape:
-
block6c_se_reshape (Reshape): Reshapes for SE.
- Input shape:
(None, 1152) - Output shape:
(None, 1, 1, 1152)
- Input shape:
-
block6c_se_reduce (Conv2D): Reduces channels in SE.
- Input shape:
(None, 1, 1, 1152) - Output shape:
(None, 1, 1, 48)
- Input shape:
-
block6c_se_expand (Conv2D): Expands channels in SE.
- Input shape:
(None, 1, 1, 48) - Output shape:
(None, 1, 1, 1152)
- Input shape:
-
block6c_se_excite (Multiply): Multiplies with SE output.
- Input shape:
[(None, 7, 7, 1152), (None, 1, 1, 1152)] - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6c_project_conv (Conv2D): Projects features.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 192)
- Input shape:
-
block6c_project_bn (BatchNormalization): Normalizes projected features.
- Input shape:
(None, 7, 7, 192) - Output shape:
(None, 7, 7, 192)
- Input shape:
-
block6c_drop (Dropout): Applies dropout.
- Input shape:
(None, 7, 7, 192) - Output shape:
(None, 7, 7, 192)
- Input shape:
-
block6c_add (Add): Adds the input of the block to its output (skip connection).
- Input shape:
[(None, 7, 7, 192), (None, 7, 7, 192)] - Output shape:
(None, 7, 7, 192)
- Input shape:
Block 6d
This block continues the pattern of expansion, depthwise convolution, SE block, projection, dropout, and an additive skip connection.
-
block6d_expand_conv (Conv2D): Expands channels.
- Input shape:
(None, 7, 7, 192) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6d_expand_bn (BatchNormalization): Normalizes expanded features.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6d_expand_activation (Activation): Activates expanded features.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6d_dwconv (DepthwiseConv2D): Performs depthwise convolution.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6d_bn (BatchNormalization): Normalizes depthwise convolution output.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6d_activation (Activation): Activates depthwise convolution output.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6d_se_squeeze (GlobalAveragePooling2D): Global average pooling for SE.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 1152)
- Input shape:
-
block6d_se_reshape (Reshape): Reshapes for SE.
- Input shape:
(None, 1152) - Output shape:
(None, 1, 1, 1152)
- Input shape:
-
block6d_se_reduce (Conv2D): Reduces channels in SE.
- Input shape:
(None, 1, 1, 1152) - Output shape:
(None, 1, 1, 48)
- Input shape:
-
block6d_se_expand (Conv2D): Expands channels in SE.
- Input shape:
(None, 1, 1, 48) - Output shape:
(None, 1, 1, 1152)
- Input shape:
-
block6d_se_excite (Multiply): Multiplies with SE output.
- Input shape:
[(None, 7, 7, 1152), (None, 1, 1, 1152)] - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block6d_project_conv (Conv2D): Projects features.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 192)
- Input shape:
-
block6d_project_bn (BatchNormalization): Normalizes projected features.
- Input shape:
(None, 7, 7, 192) - Output shape:
(None, 7, 7, 192)
- Input shape:
-
block6d_drop (Dropout): Applies dropout.
- Input shape:
(None, 7, 7, 192) - Output shape:
(None, 7, 7, 192)
- Input shape:
-
block6d_add (Add): Adds the input of the block to its output (skip connection).
- Input shape:
[(None, 7, 7, 192), (None, 7, 7, 192)] - Output shape:
(None, 7, 7, 192)
- Input shape:
Block 7a
This block includes expansion, depthwise convolution, SE block, and projection.
-
block7a_expand_conv (Conv2D): Expands channels.
- Input shape:
(None, 7, 7, 192) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block7a_expand_bn (BatchNormalization): Normalizes expanded features.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block7a_expand_activation (Activation): Activates expanded features.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block7a_dwconv (DepthwiseConv2D): Performs depthwise convolution.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block7a_bn (BatchNormalization): Normalizes depthwise convolution output.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block7a_activation (Activation): Activates depthwise convolution output.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block7a_se_squeeze (GlobalAveragePooling2D): Global average pooling for SE.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 1152)
- Input shape:
-
block7a_se_reshape (Reshape): Reshapes for SE.
- Input shape:
(None, 1152) - Output shape:
(None, 1, 1, 1152)
- Input shape:
-
block7a_se_reduce (Conv2D): Reduces channels in SE.
- Input shape:
(None, 1, 1, 1152) - Output shape:
(None, 1, 1, 48)
- Input shape:
-
block7a_se_expand (Conv2D): Expands channels in SE.
- Input shape:
(None, 1, 1, 48) - Output shape:
(None, 1, 1, 1152)
- Input shape:
-
block7a_se_excite (Multiply): Multiplies with SE output.
- Input shape:
[(None, 7, 7, 1152), (None, 1, 1, 1152)] - Output shape:
(None, 7, 7, 1152)
- Input shape:
-
block7a_project_conv (Conv2D): Projects features.
- Input shape:
(None, 7, 7, 1152) - Output shape:
(None, 7, 7, 320)
- Input shape:
-
block7a_project_bn (BatchNormalization): Normalizes projected features.
- Input shape:
(None, 7, 7, 320) - Output shape:
(None, 7, 7, 320)
- Input shape:
Top Layers and Output
These layers finalize feature extraction and produce the model’s predictions.
-
top_conv (Conv2D): Applies a convolutional layer to the final features.
- Input shape:
(None, 7, 7, 320) - Output shape:
(None, 7, 7, 1280)
- Input shape:
-
top_bn (BatchNormalization): Normalizes the output of the top convolution.
- Input shape:
(None, 7, 7, 1280) - Output shape:
(None, 7, 7, 1280)
- Input shape:
-
top_activation (Activation): Applies an activation function to the normalized output.
- Input shape:
(None, 7, 7, 1280) - Output shape:
(None, 7, 7, 1280)
- Input shape:
-
avg_pool (GlobalAveragePooling2D): Performs global average pooling to reduce spatial dimensions.
- Input shape:
(None, 7, 7, 1280) - Output shape:
(None, 1280)
- Input shape:
-
top_dropout (Dropout): Applies dropout for regularization before the final prediction.
- Input shape:
(None, 1280) - Output shape:
(None, 1280)
- Input shape:
-
predictions (Dense): The final dense layer producing the model’s output (e.g., class probabilities).
- Input shape:
(None, 1280) - Output shape:
(None, 1000)
- Input shape:
print(model) output
PS: Labeled Python for syntax highlighting.
EfficientNet(
(features): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Sequential(
(0): MBConv(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(32, 8, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(8, 32, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(2): Conv2dNormActivation(
(0): Conv2d(32, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.0, mode=row)
)
)
(2): Sequential(
(0): MBConv(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(16, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(96, 96, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=96, bias=False)
(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(96, 4, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(4, 96, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(96, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.0125, mode=row)
)
(1): MBConv(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(24, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(144, 144, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=144, bias=False)
(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(144, 6, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(6, 144, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(144, 24, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.025, mode=row)
)
)
(3): Sequential(
(0): MBConv(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(24, 144, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(144, 144, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=144, bias=False)
(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(144, 6, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(6, 144, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(144, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.037500000000000006, mode=row)
)
(1): MBConv(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(40, 240, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(240, 240, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=240, bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(240, 10, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(10, 240, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(240, 40, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(40, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.05, mode=row)
)
)
(4): Sequential(
(0): MBConv(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(40, 240, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(240, 240, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=240, bias=False)
(1): BatchNorm2d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(240, 10, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(10, 240, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(240, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.0625, mode=row)
)
(1): MBConv(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(80, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(480, 480, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(480, 20, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(20, 480, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(480, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.07500000000000001, mode=row)
)
(2): MBConv(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(80, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(480, 480, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(480, 20, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(20, 480, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(480, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(80, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.08750000000000001, mode=row)
)
)
(5): Sequential(
(0): MBConv(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(80, 480, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(480, 480, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=480, bias=False)
(1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(480, 20, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(20, 480, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(480, 112, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.1, mode=row)
)
(1): MBConv(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(112, 672, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(672, 672, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=672, bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(672, 28, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(28, 672, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(672, 112, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.1125, mode=row)
)
(2): MBConv(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(112, 672, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(672, 672, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=672, bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(672, 28, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(28, 672, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(672, 112, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.125, mode=row)
)
)
(6): Sequential(
(0): MBConv(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(112, 672, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(672, 672, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), groups=672, bias=False)
(1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(672, 28, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(28, 672, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(672, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.1375, mode=row)
)
(1): MBConv(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(192, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(1152, 1152, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=1152, bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(1152, 48, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(48, 1152, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(1152, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.15000000000000002, mode=row)
)
(2): MBConv(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(192, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(1152, 1152, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=1152, bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(1152, 48, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(48, 1152, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(1152, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.1625, mode=row)
)
(3): MBConv(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(192, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(1152, 1152, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=1152, bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(1152, 48, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(48, 1152, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(1152, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.17500000000000002, mode=row)
)
)
(7): Sequential(
(0): MBConv(
(block): Sequential(
(0): Conv2dNormActivation(
(0): Conv2d(192, 1152, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(1): Conv2dNormActivation(
(0): Conv2d(1152, 1152, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1152, bias=False)
(1): BatchNorm2d(1152, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
(2): SqueezeExcitation(
(avgpool): AdaptiveAvgPool2d(output_size=1)
(fc1): Conv2d(1152, 48, kernel_size=(1, 1), stride=(1, 1))
(fc2): Conv2d(48, 1152, kernel_size=(1, 1), stride=(1, 1))
(activation): SiLU(inplace=True)
(scale_activation): Sigmoid()
)
(3): Conv2dNormActivation(
(0): Conv2d(1152, 320, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(stochastic_depth): StochasticDepth(p=0.1875, mode=row)
)
)
(8): Conv2dNormActivation(
(0): Conv2d(320, 1280, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1280, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): SiLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=1)
(classifier): Sequential(
(0): Dropout(p=0.2, inplace=True)
(1): Linear(in_features=1280, out_features=1000, bias=True)
)
)