Automatic Knowledge Graph Construction with LLMs for Hybrid Retrieval and Chatbot Integration
Access Links
- 👨💻 Code: yuk068/hybridgrag-chatbot
- 📃 Report + Poster + Slides: Drive - LLMKG_Project
- 🎥 Live Presentation: Youtube - Yuk
- ⌛ The project spanned from around the start of April, 2025 till the middle of May, 2025.
Prologue
This was my work for the MAT1204 - Research Methodology course at HUS - VNU-an academic style report: Automatic Knowledge Graph Construction with LLMs for Hybrid Retrieval and Chatbot Integration. The project was quite impactful towards my growth, whether it be positive or negative. Throughout this project, I was able to pretty much grasp the entire LLM + integration/application field of research, from how expansive the landscape of LLMs actually is (proprietary, open-source, varying sizes, etc…)-to working with them and various integrations (RAG, Knowledge Graph, Prompt Engineering, etc…). The end product is simply a pseudo pipeline that goes from automatically constructing a knowledge graph from documents, to a hybrid RAG+KG mechanism for chatbot integration, in order to formally evaluate the pipeline, I benchmarked it with the MultiHop-RAG benchmark (Tang & Yang., 2024) using Qwen 2.5 models and Mistral 7B for LLM-as-a-judge.
Not only was the depth and breath of the insights gained substantial, I also had the chance to gauge my own capability considering I worked on this end-to-end all on my own. Nevertheless, this project also involved a lot of disillusionment and negativity that-quite frankly-made me don’t really know how to feel about it at the end, which is what I’m going to try to articulate in this post. Spoiler alert it involves a not so pleasant experience with my “supervisor” and basically made me lost any hope I had left in terms of growth opportunity within my own university, shucks 😐.
Table of Content
Block
Project Overview
First and foremost, I want to briefly go over the technical details of the paper, no drama or personal exposition here yet 😐. This section will basically be a recap of the paper, serves as a refresher for me writing this as well I guess. Most of the technical details have been covered in the report already so I won’t go too in depth here.
Abstract
BlockLarge Language Models (LLMs) powering chatbots often struggle with factual accuracy, especially for specific or recent information, leading to hallucinations. Retrieval-Augmented Generation (RAG) addresses this, but standard methods retrieving unstructured text chunks can be insufficient for complex queries. This work presents a system for enhancing chatbot reliability through automatic Knowledge Graph (KG) construction using LLMs. We detail an offline process where LLMs extract entities and relations from documents to populate a KG (stored in Neo4J), linking structured knowledge back to source text. In the online phase, user queries trigger a hybrid retrieval mechanism, combining targeted graph traversal with semantic document chunk searching. This enriched context is then fed to an LLM-based chatbot for answer generation. Evaluations using Qwen 2.5 models demonstrate that this hybrid approach outperforms baseline models and RAG variants using only graphs or only chunks, leading to more accurate and grounded responses. However, building the KG pipeline autonomously proved empirically challenging, requiring substantial manual tuning and safeguards due to the brittleness of current LLM-based extraction methods.
Motivation & Related Works
Hallucinations in LLMs, is basically when a language model provide an answer that is jarringly incorrect or inappropriate compared to the given query-often very confidently so. In order to make LLMs more reliable in actual applications, one of the prominent recent innovation is RAG (Retrieval Augmented Generation). Defogging all the fluff, RAG is basically: giving the LLM more context to work with, for example, when you are asking ChatGPT something, say:
User's Prompt: *"What is the relationship between John and Jane."*
Obviously no LLM is gonna know who John and Jane is in this prompt, larger and smarter models would most likely point this out and ask you to give it more context, but smaller language models or SLMs (Small Language Model) (~1B-7B), especially heavily quantized ones, it might confidently return an answer like this:
Model's Answer: *"John and Jane are siblings that has lived together since 2009."*
But know, with RAG, the interaction might look something like this:
You are an internal company assistant. Answer questions based only on the provided context. If the information is not available, say you don't know.
Retrieved Context:
...In the 2023 Q4 product strategy review, John Smith from Marketing collaborated closely with Jane Doe, the lead Product Designer, to align the go-to-market messaging with the new design system. Their joint initiative led to a 15% boost in feature adoption within the first month of release. John praised Jane's attention to user feedback, while Jane appreciated John's clear articulation of marketing goals..."
User's Prompt: *"What is the relationship between John and Jane?"*
Model's Answer: *"John and Jane have a professional relationship; they collaborated during the 2023 Q4 product strategy review, where John represented Marketing and Jane was the lead Product Designer."*
This is what is usually called Naive RAG, where the retrieved context is unstructured, and is dependant on an embedding model. Text Embedding Models, in tandem with LLMs, are neural networks that takes in a text, and produces a fixed size vector representation, if you are familiar with TF-IDF or BOW, its quite similar. Vectors produced by embedding models are semantically rich as compared to the keyword-based approach of TF-IDF and BOW, resolving some of their limitations, especially when performing similarity search, because of the way these embedding models are trained, it allows us to directly search semantically similar text from the user’s prompt.
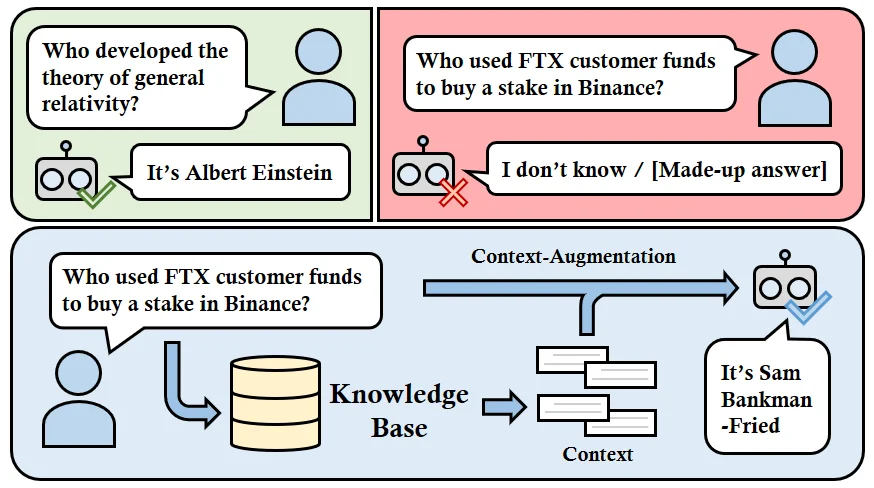
However, Naive RAG’s simplicity can also leads to its failure sometimes, especially when the retrieved text is semantically similar, but irrelevant, for example:
You are an internal company assistant. Answer questions based only on the provided context. If the information is not available, say you don't know.
Retrieved Context:
...In the 2021 team offsite event, John Smith gave a talk about cross-functional collaboration. The talk was well-received by the audience. Jane Doe, who joined the company two months later, hosted a panel on inclusive design in early 2022. Both events were part of the company’s continuous learning initiative...
User's Prompt: *"What is the relationship between John and Jane?"*
Model's Answer: *"John and Jane both participated in the 2021 team offsite event, where they discussed collaboration and design."*
The issue here usually traces back to the fact that Naive RAG works with unstructured text. Thus, a blooming approach to address cases like these is to use structured text, most commonly with structured data like tables, and the focus of the paper: Knowledge Graphs. Compared to the unstructured text retrieval of Naive RAG, a retrieval with structured knowledge using a knowledge graph might look something like this:
You are an internal company assistant. Answer questions based only on the provided context. If the information is not available, say you don't know.
Retrieved Context:
[Person: John Smith] → [COLLABORATED_WITH] → [Person: Jane Doe]
[Project: Q4 Strategy Review] ← [INVOLVED_IN] ← [John Smith, Jane Doe]
[Department: Marketing] ← [BELONGS_TO] ← [John Smith]
[Department: Product Design] ← [BELONGS_TO] ← [Jane Doe]
User's Prompt: *"What is the relationship between John and Jane?"*
Model's Answer: *"John and Jane collaborated on the Q4 Strategy Review project; John is from Marketing and Jane is from Product Design."*
This is the most basic idea of the paper, we are trying to achieve something similar to the workflow above, and maybe even, combine both approaches: RAG + KG, for a hybrid retrieval pipeline.
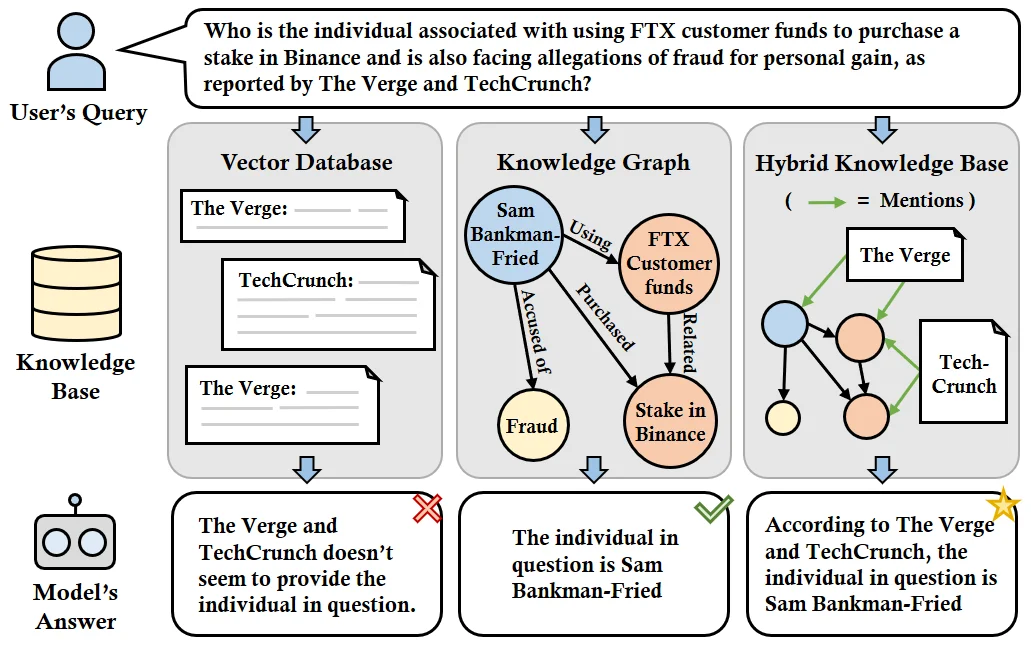
Methodology & Decisions
Because its a pseudo-paper, this is what I planned to do:
- Pick a QA retrieval benchmark, one that comes with a text corpus.
- Construct a huge knowledge graph from the corpus, using LLM.
- With the KG, engineer a hybrid RAG + KG pipeline.
- Evaluate with the QA set, 4 approaches: no context, RAG, KG, and Hybrid.
- LLM-as-a-judge for nuanced evaluation.
Hybrid Pipeline
The Hybrid Retrieval pipeline combines structured and unstructured retrieval to support accurate, verifiable QA. The system is built using LangChain for orchestration, Neo4j as the graph backend, and LM Studio to easily test multiple models and to serve LLM endpoints. Models and embeddings are accessed via HuggingFace.
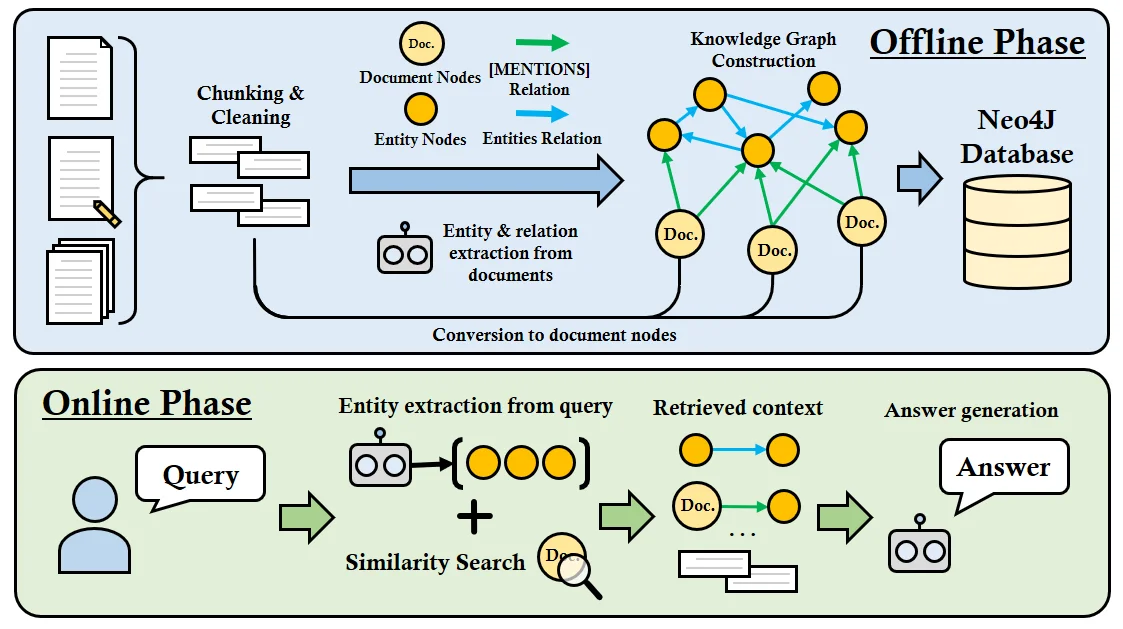
Figure 3 (Pham., 2025) Full pipeline for Hybrid Knowledge Graph RAG. (Offline Phase) Raw documents undergo Chunking & Cleaning, followed by LLM-driven Entity & Relation Extraction. A Knowledge Graph is constructed, linking entities, their relationships, and mapping entities back to their source Document Nodes via ‘[MENTIONS]’ relations. This graph is stored in a Neo4J Database. (Online Phase) A user Query triggers Entity Extraction and Similarity Search against the Knowledge Graph. Relevant context (graph structure and and associated document text) is Retrieved and fed to the LLM for final Answer Generation.
BlockNeo4J: a high-performance, open-source graph database designed to store and query data as nodes, relationships, and properties. Unlike traditional relational databases, Neo4j uses the property graph model, enabling fast and intuitive traversal of relationships, which is particularly useful for applications like recommendation systems, fraud detection, and knowledge graphs.
Operations
Offline Phase (Preprocessing & Graph Construction):
- Chunking & Cleaning: Raw documents are segmented and normalized for processing.
- Entity & Relation Extraction: An LLM identifies entities and their relationships; each entity is linked back to its document via [MENTIONS] edges.
- Graph Building: The extracted triples and source mappings are assembled into a Neo4j Knowledge Graph.
Online Phase (Query-Time Execution):
- Entity Extraction: The user query is analyzed by an LLM to identify key entities.
- Retrieval:
- Graph Search: Full-text matching retrieves relevant subgraphs and associated [MENTIONS] document nodes.
- Similarity Search: Cosine similarity identifies semantically relevant nodes.
- Answer Generation: Retrieved context (triples + text) is injected into the LLM prompt using a simple context augmentation format: Query + Retrieved Context + Instruction → Answer.
Experiment
To evaluate the pipeline, I used the MultiHop-RAG benchmark (Tang & Yang., 2024)—a dataset designed to test multi-hop reasoning in Retrieval-Augmented Generation systems. From the benchmark’s 609 news articles, we performed word-level chunking into 180-word segments with 30-word overlaps to prepare the data for processing. Knowledge graph construction was powered by Qwen 2.5 7B (Q4 quantized) and embedding model used is Nomic Embed Text v1.5 (Q8 quantized). The offline phase took approximately 14 hours, resulting in a graph with over 50,000 nodes and 120,000 edges, capturing both entity relationships and source document links.
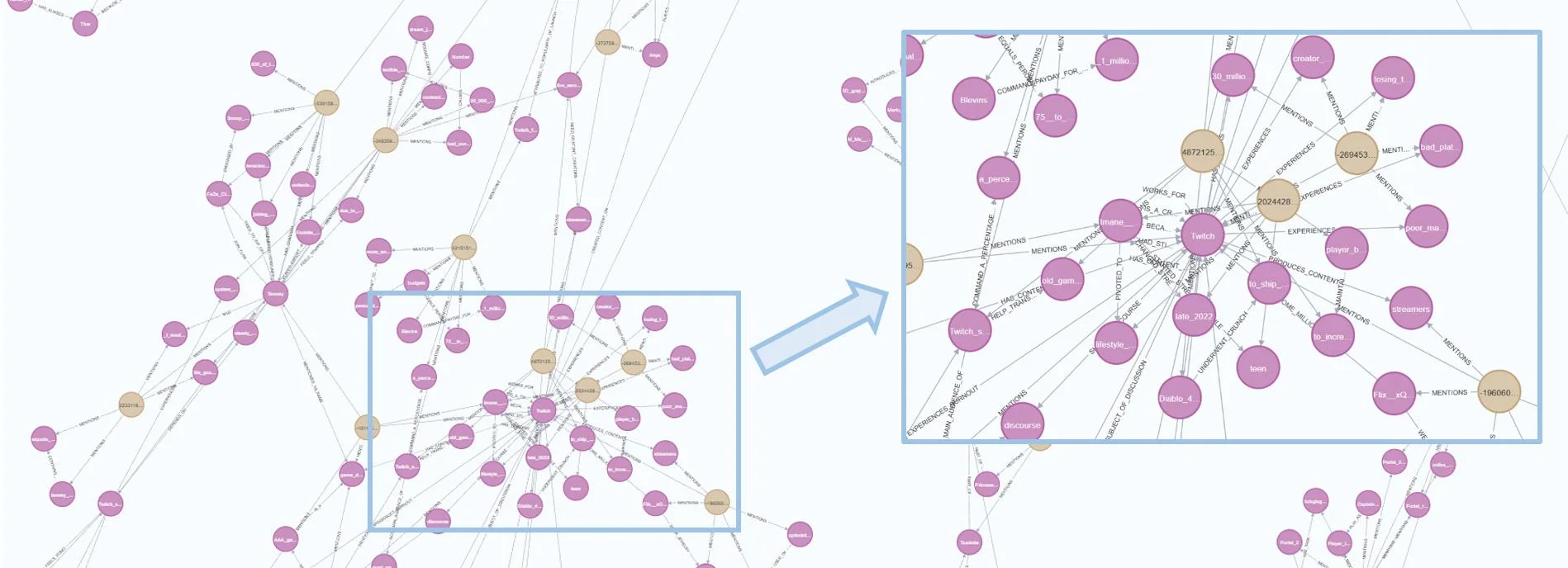
Figure 4 (Pham., 2025) Neo4j Visualization of the Knowledge Graph Constructed from the MultiHop-RAG Corpus. This figure displays a segment of the knowledge graph generated during the Offline Phase (Figure 3) from the MultiHop-RAG benchmark dataset and stored in Neo4j.
Evaluation
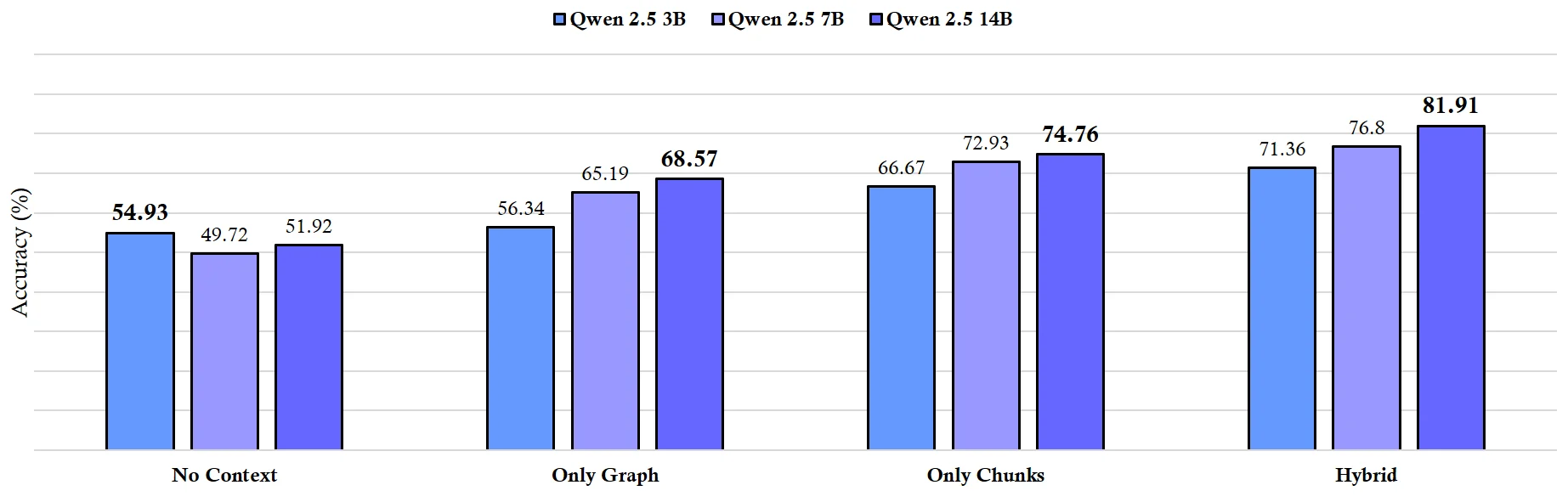
Figure 5 (Pham., 2025) Accuracy Evaluation on the MultiHop-RAG QA Subset (10%). This chart compares the performance of Qwen 2.5 models (3B, 7B, 14B) at Q4 quantization when evaluated on 10% of the MultiHop-RAG question-answering dataset, using different context strategies: No Context (baseline), Only Graph, Only Chunks, and Hybrid. The results demonstrate that providing context boosts accuracy. The Hybrid method consistently achieves the highest scores across all model sizes, with larger models (14B) generally performing best and benefiting most from the Hybrid strategy.
Conclusion
Combining structured reasoning with source-grounded evidence shows strong potential for improving LLM accuracy on complex, multi-hop queries. Results demonstrate clear gains over simpler retrieval strategies, especially when larger models are used with hybrid context. However, this comes with trade-offs, high compute demands, long processing times, and heavy reliance on LLMs for graph construction make the approach costly and hard to scale. Future work should focus on stronger safeguards, more robust and modular pipelines, and minimizing reliance on LLMs-especially smaller or quantized ones-for critical tasks. Shifting key operations to deterministic or lightweight components could improve both efficiency and reliability.
Yuk Lore
This is gonna be one hell of a story so buckle up lol.
If you recall (I wrote it somewhere idk), this semester (2nd semes of 2nd year), I signed up for 3 project-driven courses, basically courses that are graded mostly with a final project. Thus, this project is used for two courses (at first I was wanting 1 mega project to tackle all 3, something to do with multimodal AI).
Thats the broader context, now, about this course, this the MAT1204 - Research Methodology course. In this course, you will have about a 4 weeks “grace period” where all you really do is attend lectures about “how to do research”-things like planning, risk management, citation, ethics, and so on. And for my class the teach enforced hand-written regurgitation notes lol. After this period, you will have to start thinking about what kind of project/research you’d do, the goal of the course is afterall:
- Attend the student’s scientific conference: You’d have to pretty much have everything about the project figured out, a poster, and you present to it in front of ppl, you just dont have to write a paper formally yet.
- Produce an academic style paper: Gather everything and produce a scientific report/paper, it could either be one of those “đóng quyển” report or something like an arxiv style paper, up to you, as long as you cover the core fundamentals-to deliver a good “research”.
Now, that might sound all grand and cool, but imma just come out and say, its really like a makeplay session. Disclaimer: I can only speak from my experience, which is within my faculty (facl of math n stuff), im sure others are different. But, I really felt like this whole ordeal was nothing but a pretend play as if this stuff actually mean anything. (Redacted because the school board might get my ass, go on, make my life more difficult lol).
But yeah, I came in with excitement and high hopes, how stupid of me lol, from this school? This, was the moment, the experience, that drive my hope for my own school to absolute 0. But, im getting ahead of myself, what actually happened? So, remember, at first I was looking at multimodal AI, I was already doing some research I think even before the course, like I was looking at VQA (visual question answering), and various tasks/domain like legal, medical, etc… But, at that point things still seem pretty uncertain to me because compute was a big reason why I couldn’t go big in terms of grandiose.
So yeah, I was already quite prepared, I tried open-source and local LLMs for the first time, mess around with calling API endpoints and interacting with LLMs that is not in a chat interface. When it came time to find a professor to be your supervisor, a few caught my eye, but eventually I decided to pitch for a proposal: LLMs with structured knowledge. Sounds cool and have potential, boy was i wrong.
After deciding on that, I mailed the prof which was an associate professor btw, he accepted to hear my pitch on campus, and the talk went pretty great that day, I really thought he someone saw my mindset, grades are not that amazing, but I have drive and I was just a second year and im already doing all this shit. But, after that talk, I went home and asked him for a few reference, he sent me like an expired langchain blogpost that gives 404.
Alright sure, I mean, I have been alone before, and I guess NOT being alone would be a miracle for me-i thought. So, I did my own digging anyway, I delved into it and still had the whole multimodal thing in my mind, perhaps in some kind of retrieval system, or even a medical imaging platform that has a natural language interface. Whatever I was on I remember it was deep, I reviewed like idk 80+ papers? If there was one thing that I was able to take away from this experience is a broad understanding of the entire field of LLM and application.
But yeah, when doing these literature review, I shared everything along the way with the prof, I dont think he has ever reply to any one of those discussion that i was longing to have. Now, I can say this: shits would have been a lot easier and faster, if i didnt have more aspiration, because, just reimplementing stuff, or creating something that i dont believe is meaningful, i did not want to do any of that. Come to think of it, he did replied once and it was to tell me to do what i just list out-reimplement a paper, make a dataset, lol. Idk about you, but,… you know, abandonment is a quite prominent in my life, from parents, to friends, etc… he was triggering something i guess.
But, being stuck with this deadbeat and the deadline closing in (i wanted to be able to attend the conference (again its more like a makeplay) formally so bad). I tried to push through, I put all my strength into it, went down every single intuition and rabbit hole, but then, another bad luck, this field is NOT serious lmao. Like the whole LLM application field, RAG and shits, I have made some post about it before, but basically, only when you are deep into it do you realize theres jack shit to do here for us peebs, its just the big coorps that can do anything meaningful. And if its not from a big coorps, then its mostly just fluff and buzzword, doesnt not really contribute to anything at all.
So yeah, everything was stacked against me, but i still push through, and tried to make for something presentable, which is this project here. Im not gonna lie, i wont say that im all right, Im sure perhaps theres some kind of norm-standard for students working with profs, or a better research flow had i not been alone. I did fall into some rabbit hole and tried to push some pretty bullshit unproven stuff lol, can you blame me though, luckily this project is still somewhat grounded. But, as you can see, shits was bad, I had about 3 nights that i did not sleep, i just sat through the night and tried everything that i can to have some sort of deliverables.
The day for the deadline of the conference come, i did not sleep that day, he was still nowhere to be seen, so i went on campus, looking for him, cant find him again, at this point, i was pretty tired and my mind wasnt straight, so i asked for others in the faculty to give me some advice. You know, best of respect to them, but, now i realized, these people dont care if you are okay or not lol, they only care if you listen to their shits or not. Yeah this about the point that my hope is shattered, when my mentality switched to “lets just get this shit over with”. Like a day after the deadline, he just say my shit was not ready and that i should not attend (pretty sure the dude implied i should just quit CS altogether lol).
But yeah, what comes after is me finishing this project to the degree that you can see. I still push through, still attend the conference even if my name wasnt in the list, still tried to make everything up to standard despite being alone (of course i didnt put his name in anywhere). And eventually presented the project to the 2 courses that i planned to and got decent grades.
By the way, funny story, like between the conference (midterm) and the finals, he did ask to meet me on campus a second time (yes this is THE SECOND TIME we meet face to face during a semester). I presented the end product of what i was eventually able to achieve, he brush it off positively i guess, talk sweet about some lending gpu or applying this to the school addmission chatbot or something (fuck no dont go into this faculty kids). But yeah, all talk, i never heard from this guy again.
I honestly dont care if im burning bridges or some shit (perhaps i am with this post lmao), but, i had enough, i dont want to tolerate more, i dont think that im worthless or that im not capable of moving towards where i believe that i need to be. I dont care about norms and frankly even the academic culture shit, im pretty sure most of the people in this faculty is under that publish or perish mentality, you know, perhaps its not their fault, but I just dont want students to be wronged like this. Afterall, its also from this experience that I was able to see clearly that I dont exactly “just” want to be an engineer or a researcher, I think my aspiration might lie somewhere in between lol. And for this school, this faculty? I decided that, im not stuck here, I dont care about “what ifs” shits like what if i went to a different school back then anymore, Im going to move forward, towards what I believe in. If it brings some positivity to this story, right now im looking for internship and actual jobs, actual opportunities, now that I feel that im genuinely ready after having faced shits like this before. This school? just gonna do the bare minimum to get by (I still get good grades on courses that i believe matter), but yeah this school is just a degree sale organization to me at this point.
Alright look, if you are able to sit through this until now-i will admit: i dont know if im wrong, right, or if there is any wrong or right in this story, should there be? Im not asking for empathy or compassion “yea you show them” type shit, im also not trying to attack anyone. Its just that, it just saddens me, what if, someone was like me, ambitious and hopeful, only needing some guidance, what if they didnt had the strength that i had? what if when he said i should not attend, i quit right there and then? I pushed through, and still look on the bright side of experience gained and lessons learned all on my own, but, they say pain builds character n shits, i want to counter that: its not always necessary.
Also, Im not trying to make myself as this prodigy that people just have to give everything to, fuck no I dont think i will ever “finish” learning in the AI field. Its just that, I do feel like what you are working on can really make or break you, and me? now i realized that i want to work on what matters, what directly have impact, not these synthetic ass buzzword dressed up to be research, synthetic benchmark, synthetic dataset, LLM-related research-performed by LLM-evaluated by LLM, average NeurlIPS in 2024-2025 lol.
Again, all I want to express here, is that, when I see something that i believe was unpleasent, or that it could have been better, then i dont want to turn a blind eye to it.
Epilogue
Yeah, wild story, but then again, I gained knowledge, experience, and decided that i cant put my future into this school anymore, a win I guess. While I don’t exactly have much care for it, but I do hope that, you understand, and you feel, you can look me in whatever way you want, but please, don’t cause suffering for others. I’m not even sad because of the way I was treated, Im sad because something like this could happen to others. Perhaps Im a one in a million anomaly, perhaps Im the only one like this, thus, I deserved this, who knows lol. But, for now, while I’m still in human flesh, I won’t be able to be anything more than human, and, I will do, what a human me can-moving forward. Until next time.