Support Vector Machine (SVM) is a family of model that leverage the concept of Support Vector to find boundaries that best separate the data. The most basic usage for SVM is in binary classification with linearly separable or nearly linearly separable data. In such cases, SVM will find the most optimal hyperplane that best separate the two classes into a positive region and a negative region in relation to the two binary classes.
Moreover, SVM can also be used for regression and multiclass classification by extension of multiple binary SVM models. Most importantly, by utilizing kernel functions and the kernel trick, SVM is one of the few classical model that can handle non-linear data efficiently with unprecedented flexibility. However, SVM is noticeably prone to overfitting and both train and inference time can take exponentially longer as data grows. Furthermore by not relying on a statistical or similarity basis like that of Logistic Regression or K-NN, SVMs are also somewhat harder to interpret with its underlying geometric approach.
We will now discuss Hard Margin SVM for linearly separable data, Soft Margin SVM for nearly linearly separable data and Kernel SVM for non-linear data.
Hard Margin SVM
Linearly Separable Data
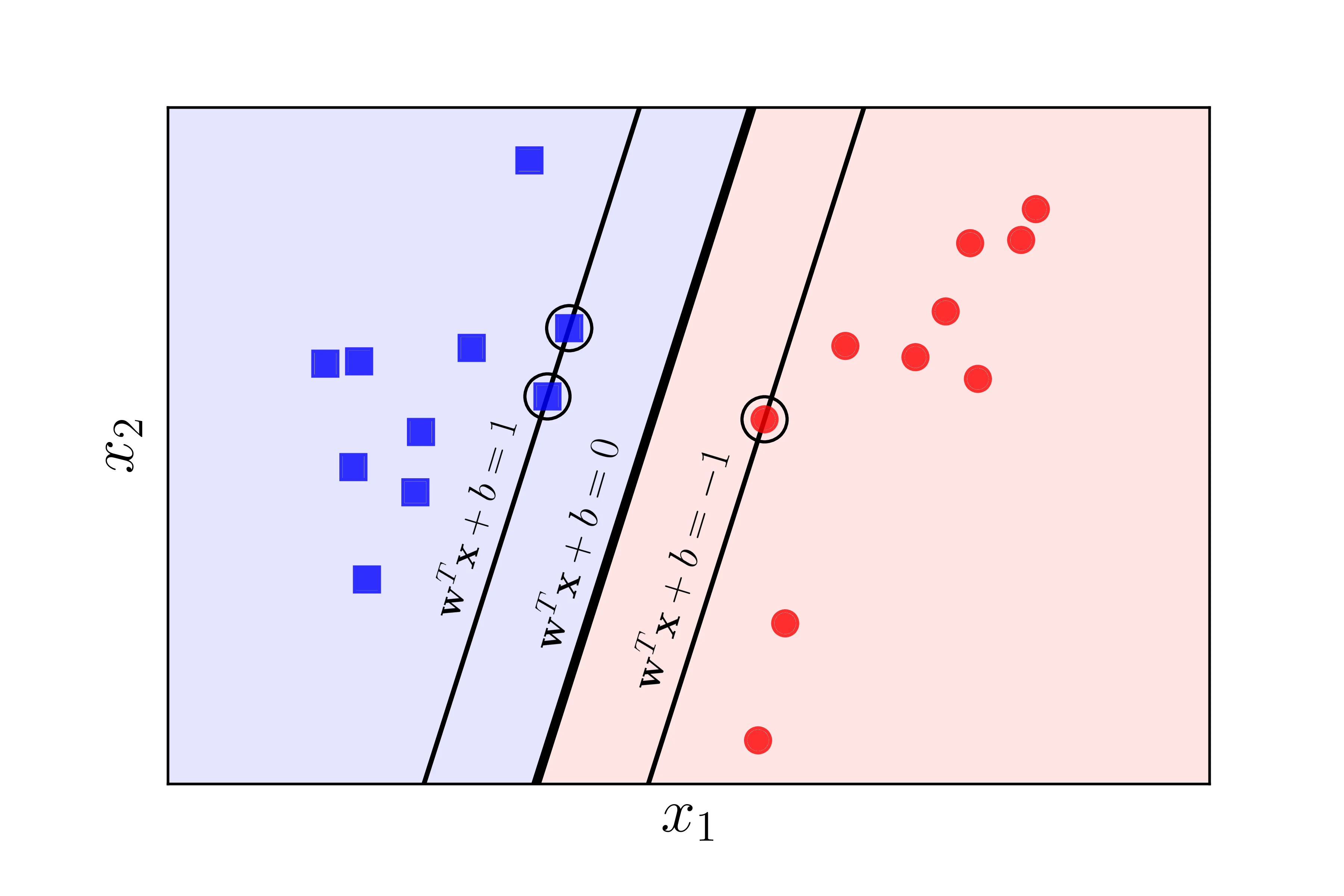
Given dataset X={(xi,yi)}i=1N where xi∈Rn and yi∈{−1,+1}, this is a binary classification task. Let X be linearly separable, assume the SVM model has already found the optimal separating hyperplane H0:w⊤x+b, we can visualize with an example in R2 (H0 is a line in this case):
We define the distance from a data point xi to H0 as:
di=∥w∥2∣w⊤xi+b∣
Block
If we remove ∣⋅∣ on the numerator and in figure 1 we define the left is the positive region (blue) and the right is the negative region (red), then we will be able to know which region does xi belongs to:
di=∥w∥2w⊤xi+b
Block
Let d+ and d− be the minimal distance from any data point from the positive and negative region respectfully that is closest to hyperplane H0. We can define the margin with width d++d− (2 slim line on both side of H0 in figure 1). For H0 to be optimal, we must ensure that no data point is inside the margin. For that, we formulate the constraints:
w⊤xi+b≥+1foryi=+1w⊤xi+b≤−1foryi=−1
Block
The constraints above can be combined into a single constraint:
yi(w⊤xi+b)−1≥0,∀i
Block
Constrained Optimization Problem
Note that w⊤xi+b=+1⟹xi∈H1:w⊤x+b=+1 and w⊤xj+b=−1⟹xj∈H2:w⊤x+b=−1. All such xi,xj are called support vectors (circled points in figure 1). Thus, we have the width of our margin as:
d++d−=∥w∥21+∥w∥21=∥w∥22
Block
The goal of hard margin SVM is to find the optimal separating hyperplane H0 while also maximizing the width of the margin, thus we formulate the constrained optimization problem:
w,bmin21∥w∥22subject toyi(w⊤xi+b)≥1,∀i(1)
Block
The constraint ensure that no data point will lie inside the margin, aiding in making sure that class +1 and −1 is perfectly separated, thus “hard margin”.
Lagrangian Dual Problem
Solving (1) directly is quite challenging, thus we derive the Lagrangian primal:
LP=21∥w∥22−i=1∑Nαi[yi(w⊤xi+b)−1](2)
Block
Where α={α1,α2,…,αN}∣αi≥0,∀i are the Lagrange multipliers for each data points. The most important aspect about (2) is that we can derive the Lagrangian dual problem for (1). Now we may check a few conditions that are crucial for the SVM model in general:
In (1), 21∥w∥22 is a convex function and the constraints are linear, thus (1) is a convex optimization problem. Furthermore, due to X being linearly separable, we know that:
Feasible set=∅⟹∃(w,b)∣yi(w⊤xi+b)>1,∀i
Block
Thus the Slater condition is satisfied and strong duality occurs, ensuring that the solution to the primal (2) is equivalently optimal as the solution to the dual problem:
Primal Objective Value=Dual Objective Value
Block
In (2) the Karush-Kuhn-Tucker conditions (KKT) is satisfied:
The KKT conditions is necessary and sufficient to provide us with an solution to the dual problem that is most optimal. The complementary slackness condition built from the primal and dual feasibility ensure that only support vectors will affect the solution which aligns with the objective of SVM. The stationary conditions directly help us compute w,b,α.
We may now construct the Lagrangian dual problem for (2) using the derivatives calculated from the KKT conditions, we substitute:
We can solve (4) with quadratic programming algorithms such as direct QP (O(n3)), Sequential Minimal Optimization (SMO) (O(n2)),…
Assume the quadratic solver provide us with the solution, meaning the optimal α′∈RN∣αi′≥0. Note that because of complementary slackness of KKT, all points where αi′>0 will be support vectors, assume S is the set of all support vectors, then most likely, ∣S∣<<∣X∣ and αi′=0 for all xi∈/S. Then, based on the stationary conditions, we may compute w and b:
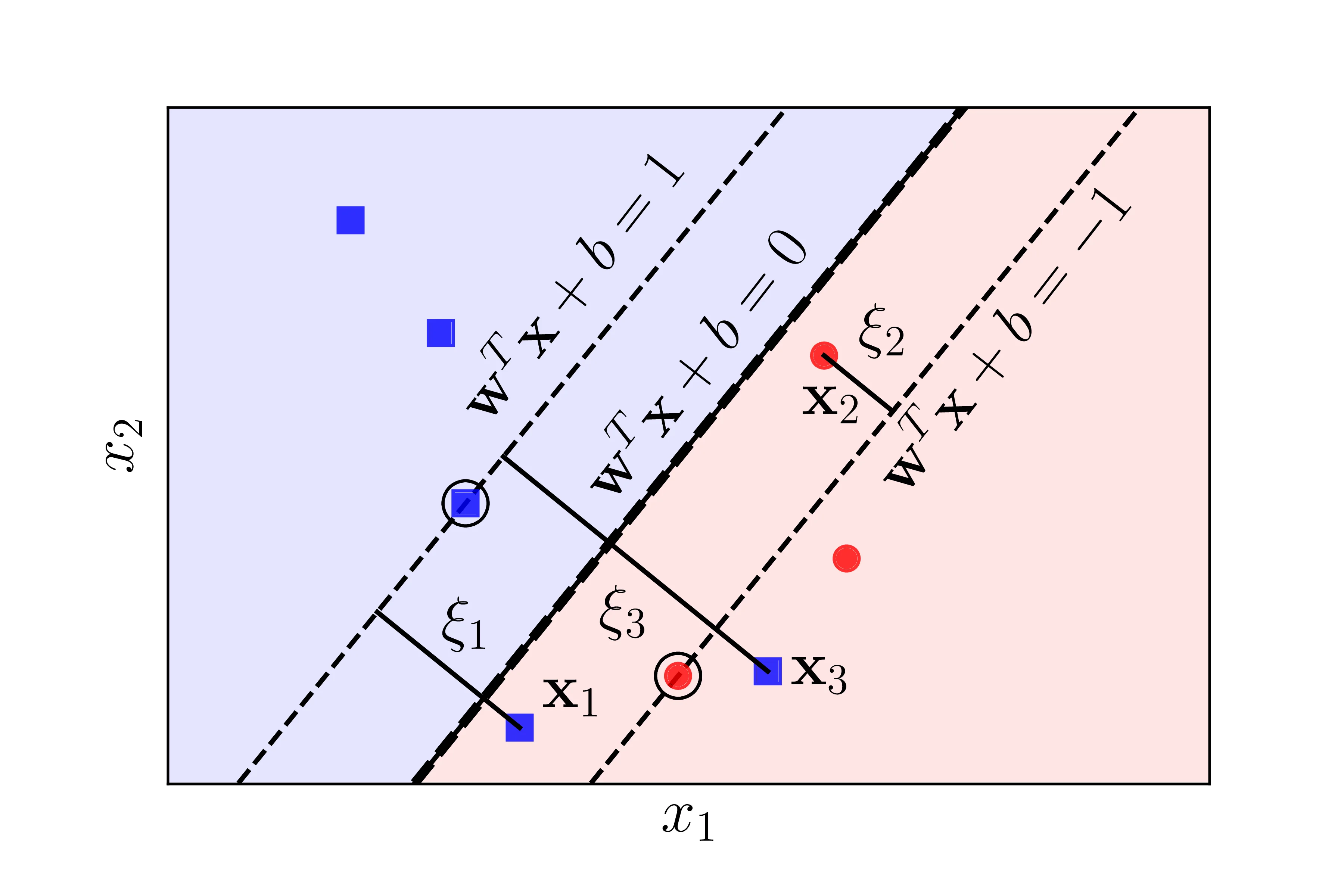
The case above is called nearly linearly separable data. For x2, the data point is dangerously close to H0 and is inside the margin. If we follow through with our constraint that all point mustn’t lie inside the margin the we would have a very narrow margin, thus reducing generalizability. For points like x1 and x3, its even impossible to construct a hyperplane that can actually completely separate the two classes.
The aforementioned drawbacks are the fundamental limitations of hard margin SVM. By not defining the constraint to be strict, we could build the soft margin SVM model to handle nearly linearly separable data. To achieve this, we introduce a slack variable ξi to the original constraints:
w⊤xi+b≥+1−ξiforyi=+1w⊤xi+b≤−1+ξiforyi=−1
Block
Combining the constraints, we have:
yi(w⊤xi+b)≥1−ξi,∀i
Block
The slack variables ξi will penalize cases where data point is inside the margin or is misclassified. The constrained optimization problem now becomes:
After which we may continue to solve using quadratic solvers just like in the hard margin case, however we may also consider the gradient descent approach in the next section which is more common for larger datasets (Note that hard margin SVM can also be solve with gradient descent).
Approach: Gradient Descent
Solving the soft margin SVM involves converting from a constrained optimization problem to an unconstrained optimization problem. First and foremost, we introduce the hinge loss:
L(y,f(x))=max(0,1−y⋅f(x))
Block
Hinge loss aligns with the object of soft margin SVM. More specifically, for correctly classified points, L=0 and for points that is inside the margin or misclassified, L>0, this characteristic directly relates to the support vectors to ensure that only such points affect the margin and the separating hyperplane. Leveraging the hinge loss, our constrained optimization problem in (5) becomes:
We perform Gradient Descent with η as the learning rate:
Step 1: Randomly initialize w,b (usually close to 0 and follows some kind of distribution).
Step 2: Calculate derivatives of J(w,b) with respect to the parameters:
∂w∂J=w−Ci=1∑N1[1−yi(w⊤xi+b)>0]yixi
Block
∂b∂J=−Ci=1∑N1[1−yi(w⊤xi+b)>0]yi
Block
Where 1[⋅] serves as an indicator function that equates to 1 if the condition in the brackets is satisfied and equates to 0 otherwise.
Step 3: Update parameters:
wnew=w−η∂w∂J
Block
bnew=b−η∂b∂J
Block
Step 4: Convergence check:
∣ΔJ∣=∣J(wnew,bnew)−J(w,b)∣<ϵ
Block
After obtaining w and b, the decision function remains similar to the hard margin svm case for query point xq:
yq=sign(w⊤xq+b)
Block
Kernel SVM
Non-Linear Data
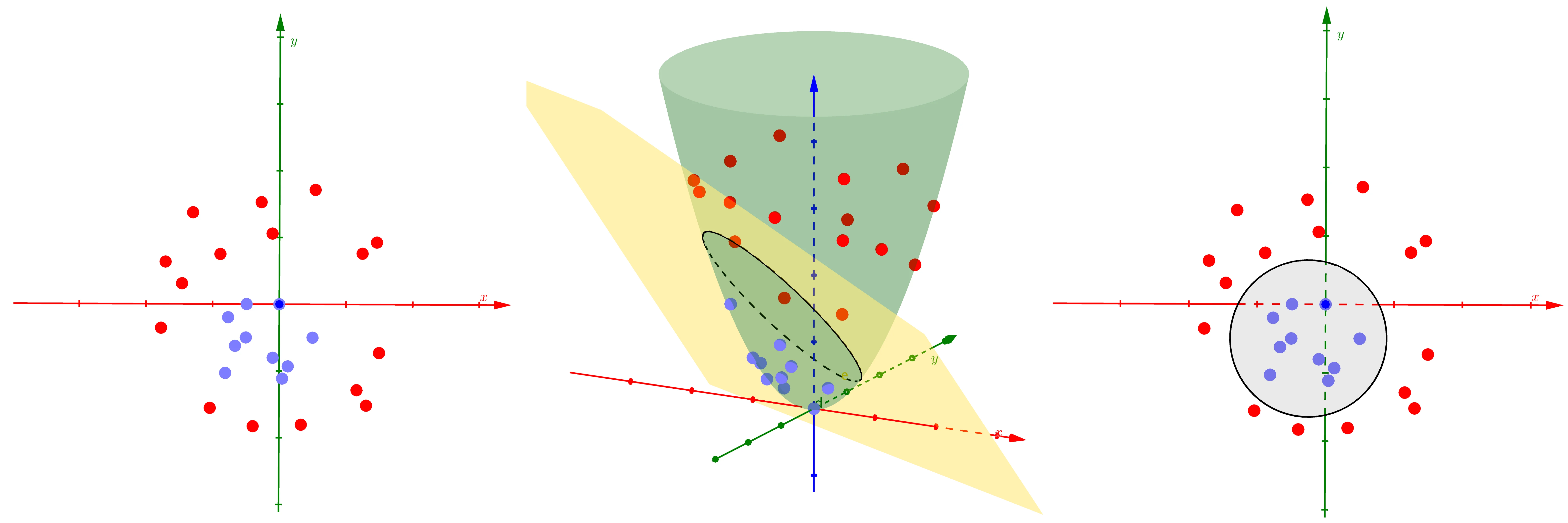
SVM can be employed for non-linear data by leveraging kernel functions and the kernel trick. Non-linear data are cases where we cannot separate the data with just a simple linear hyperplane without significant misclassification, we can observe the following example:
As we can see, on the left side is a dataset in R2 where a separating hyperplane (a line in this case) will perform horrible in separating the 2 classes. On a high level, the motivation for the kernel SVM model is that it projects the original data to a higher dimension space where the data is nearly linearly separable, after which the performance of said SVM is similar to a soft margin SVM model. In the middle, we can see that in this higher dimension space, the model still separate the data with a hyperplane (a plane in said space). On the right, after projecting back to the original dimension of the dataset, the boundaries are non-linear and will allow us to handle such non-linear data.
We see that the optimization process only depends on the inner product xi⊤xj. This observation is crucial to introduce the concept of kernel functions. Let ϕ(x) be a function where:
ϕ:Rn→Rk,ϕ(x)=(ϕ1(x),ϕ2(x),…,ϕk(x)),k∈N or k=∞
Block
Utilizing this arbitrary ϕ(x) function, our problem in (7) becomes:
Due to ϕ(x) being able to project to k∈N∪{∞} dimensions, directly calculating ϕ(x) can prove expensive or even impossible. To resolve this, note how in (8), the optimization still only depends on only the inner product ϕ(xi)⊤ϕ(xj). Thus, if we are able to find a function K(xi,xj) such that:
K(xi,xj)=ϕ(xi)⊤ϕ(xj)
Block
Then explicitly calculating ϕ(x) is unnecessary. The function K(xi,xj) is called a kernel function that can be defined by the user and must follow a few traits like symmetry, continuous, positive-semi definite and the Mercer inequality. The process of only calculating K(xi,xj) and not ϕ(x) explicitly is called the kernel trick.
A few common kernel functions:
Linear Kernel:
K(xi,xj)=xi⊤xj
Block
Polynomial Kernel:
K(xi,xj)=(γxi⊤xj+r)d
Block
Where γ, r and d are hyperparameters defined by the user.
Radial Basis Function (RBF Kernel) / Gaussian Kernel:
K(xi,xj)=exp(−γ∥xi−xj∥22)
Block
Where γ>0 is hyperparameters defined by the user.
Sigmoid Kernel:
K(xi,xj)=tanh(γxi⊤xj+r)
Block
Where γ and r are hyperparameters defined by the user.
Building the Optimization Problem
With the addition of kernel functions, the optimization problem in (8) will become:
Similar to hard and soft margin SVM, we can solve (8) with quadratic solvers. Note that we cannot solve kernel SVM with gradient descent anymore, a limitation that often leads to kernel SVM having exponentially longer training and inference time as data grows.
Final Model
Instead of w and b, kernel SVM directly use the Lagrange multipliers found by the quadratic solver to create prediction for query point xq:
yq=sign(i=1∑NαiyiK(xi,xq))
Block
Extra: SVM for Multiclass Classification
For multiclass classification with K classes, there are 2 main approaches:
One-vs-One: Will create 2K(K−1) binary SVM models.