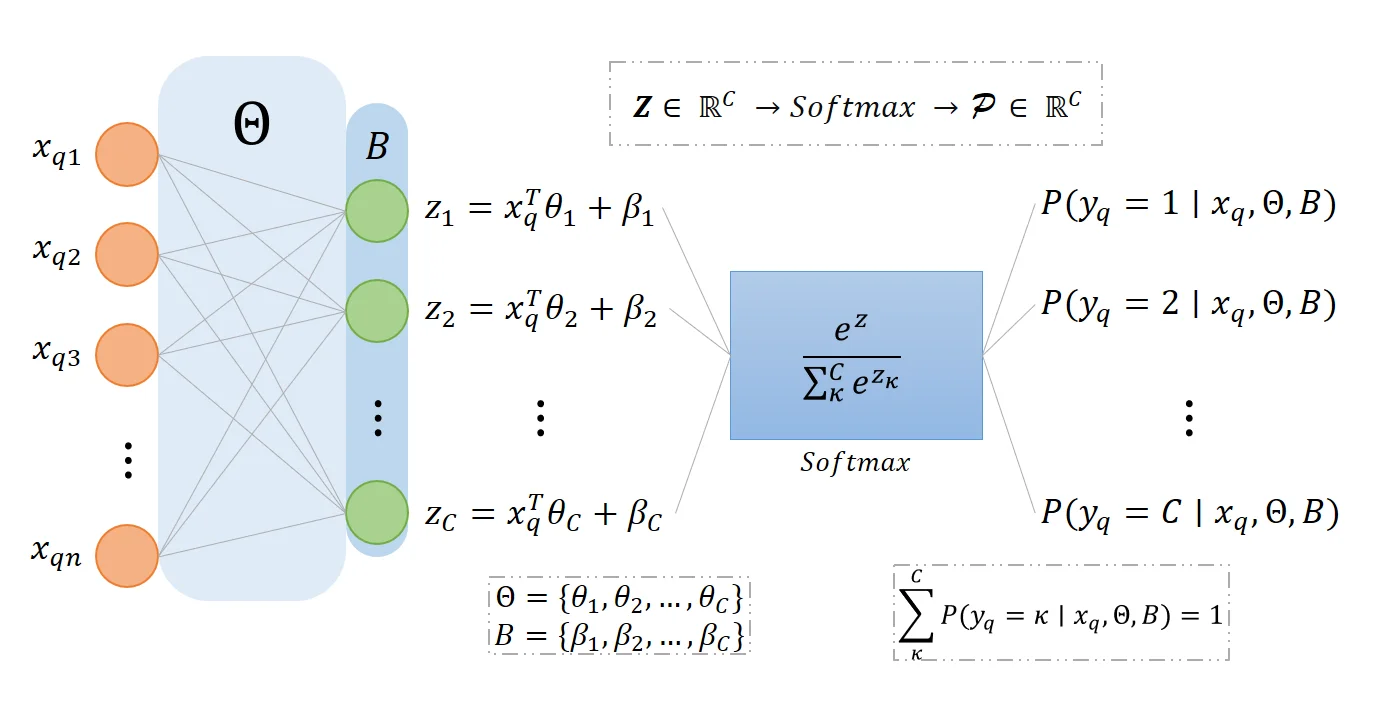
Given dataset X={(xi,yi)}i=1N where xi∈Rn and yi∈{1,2,…,C}, the Multinomial Logistic Regression model states that the likelihood of the input x belonging to class y=c is:
P(y=c∣x,Θ,B)=∑κCexp(zκ)exp(zc);zκ=xTθκ+βκ
Block
Where Θ={θ1,θ2,…,θC} are the weights and B={β1,β2,…,βC} are the biases and they make up the model’s parameters.
The set Z={z1,z2,…,zC} are called the logits for each of the C classes, which contains the linear combinations of the input x with the weights and biases.
The expression ∑κCexp(zκ)exp(zc) is the c-th element of P={P(y=1∣x,Θ,B),…,P(y=C∣x,Θ,B)} produced by the Softmax Function, in nature it maps the C linear combinations Z of the input x and the weights Θ and biases B to a probability distribution that sums up to 1. In other word, the softmax function takes Z∈RC and produces P∈RC such that ∑cCP(y=c∣x,Θ,B)=1.
Here is a visualization of the multinomial logistic regression model in the style of a neural network for queried input xq:
Our goal is to optimize the parameters Θ and B, given MLE equation:
These gradients will give us the direction of the weights and biases that will cause the steepest descent towards a local minima.
Step 3: Update parameters:
θcnew=θc+α∂θc∂Jβcnew=βc+α∂βc∂J
Block
Where α denotes the learning rate.
We perform step 2 and 3 for all logits from 1 to C.
Often times, regularization is introduced to reduce overfitting, we will focus on L2 regularization, we implement it by simply adding a regularization term into the cost function:
Jreg(Θ,B)=−N1logL(Θ,B)+2Nλc=1∑C∥θc∥22
Block
Where λ is a constant that represents the regularization strength. This will affect the weights of the model, large λ causes the weights to be closer to 0 and needs to be tune strategically to properly reduce overfitting. While the biases updates remain unchanged, our weights updates will be affected:
θcnew=θc+α∂θc∂J−Nλθc
Block
Binary Logistic Regression
When there are C=2 classes, the softmax function is reduced to a special case called the Sigmoid Function, for simplicity we let yi∈{0,1}:
undefined not callable (property 'fill' of [object Array])
Block
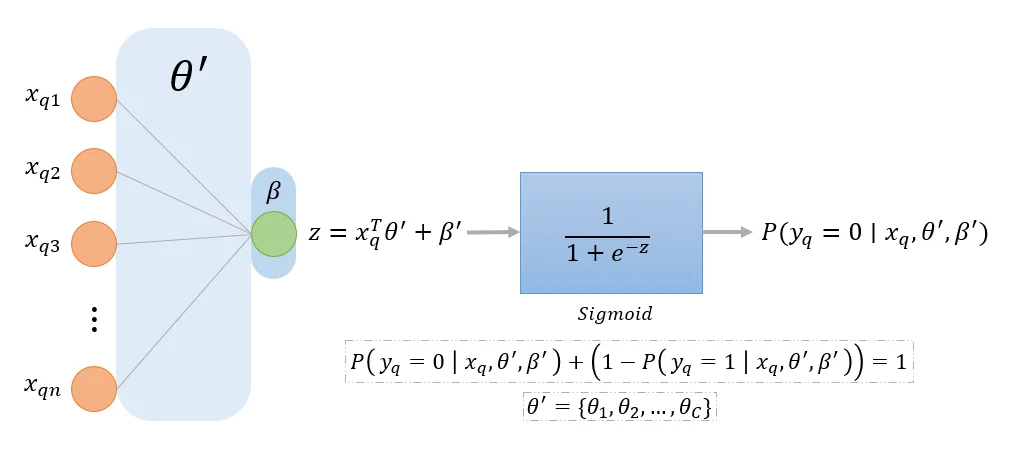
Let θ′=θ2−θ1 and β′=β2−β1, we have:
1+exp(−(xiTθ′+β′))1;1−1+exp(−(xiTθ′+β′))1
Block
Which denotes the probability of class 0 and 1 respectively, notice that both of the expressions above still sum up to 1. Therefore, when C=2, we only have to optimize for 1 set of weights θ′ and a single bias β′. Given dataset X={(xi,yi)}i=1N where xi∈Rn and yi∈{0,1}, the Binary Logistic Regression model or simply Logistic Regression model is represented as:
P(y∣x,θ,β)=(σ(z))y(1−σ(z))1−y;z=xTθ′+β′
Block
Where the weights θ′={θ1,θ2,…,θn} and bias β′∈R are the model’s parameters.
The expression σ(z)=1+exp(−z)1 denotes the sigmoid function, and z=xTθ′+β′ denotes a linear combination of the input x and the weights and bias, this function tends to 0 as z→−∞ and tends to 1 as z→+∞, and σ(z)+(1−σ(z))=1.
Here is a visualization of the binary logistic regression model in the style of a neural network for queried input xq: