Towards Building a Digital Twin for Hanoi’s Traffic System
Prologue
Okay so if you didn’t know, TrafficLab 3D originally started out as a final project for my Advanced Computer Vision course, the original academic title was “Towards Building a Digital Twin for Hanoi’s Traffic System”. So a lot of the design choice of TrafficLab actually stems from trying to adapt such a system to the reality of Hanoi, Vietnam traffic, things like mixed traffic (motorcycles), non-uniform infrastructure, etc…
But anyway, I just found an old presentation that I made before the name TrafficLab even came into the picture, so I think it should be pretty interesting especially for seeing how I approach the problem. This presentation was meant for the midterm report of the course, so it retains a lot of that Hanoi focus, it was also in Vietnamese so I’ll try to translate it neatly in this post.
Towards Building a Digital Twin for Hanoi’s Traffic System
(Original date: December 3rd, 2025)
Table of Content
Block
1. Motivation
Traffic congestion and traffic violations are increasing, creating a need for intelligent AI-powered camera systems and real-time data to support more effective traffic management.
On December 11, 2024, Hanoi approved its Smart Transportation Initiative, aiming to standardize transportation data, establish a centralized operations center, and expand digital infrastructure.
Significant investments have been allocated to camera networks and control centers, including thousands of surveillance cameras and new AI-enabled cameras, providing the foundation for a future traffic digital twin.
To move from reactive to proactive traffic management, the city requires a Digital Twin platform capable of simulation, forecasting, traffic signal optimization, and policy impact evaluation.

2. Desired Goal
Currently, AI-enabled traffic cameras in Hanoi are primarily deployed for automated traffic enforcement, commonly monitoring violations such as red-light offenses and illegal maneuvers.
These cameras are typically installed at strategic locations, such as behind stop lines at signalized intersections, and are capable of accurately identifying vehicle license plates and, in some cases, driver facial features.

The objective of this Digital Twin is not individual surveillance, but rather the modeling and analysis of mixed traffic dynamics at the system level. Instead of focusing on specific road users, the platform aims to capture how different types of vehicles interact, adapt, and move through Hanoi’s transportation network under real-world conditions.
The project is built on the premise that addressing traffic congestion requires a data-driven understanding of mobility behavior. Before effective interventions can be designed, it is necessary to understand how citizens respond to existing infrastructure, traffic regulations, and environmental constraints. By providing this understanding, the Digital Twin can serve as a foundation for simulation, forecasting, and evidence-based transportation planning.
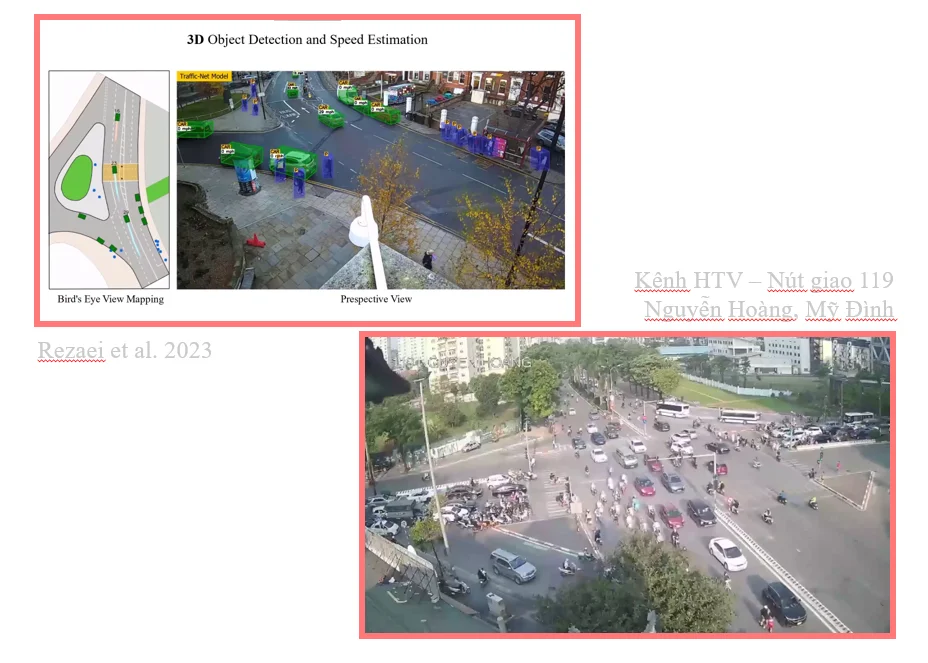
(I then showed 3D-Net Monocular 3D object recognition for traffic monitoring - Dr Rezaei. University of Leeds)
The project took inspiration from 3D-Net (Rezaei et al., 2023) to aim at building a Digital Twin for Hanoi’s Traffic System.
3. The HTVTraffic Dataset
- During the initial survey phase, publicly available traffic datasets for Hanoi were found to be extremely limited. One of the few viable sources identified was the network of wide-angle traffic cameras livestreamed on the YouTube channel of Hanoi Radio and Television (HTV). (idk if its just me but apparently the channel and the livestreams are no where to be found anymore lmaooo)
- To address this data gap, we constructed HTVTraffic, a dataset collected directly from HTV’s publicly available traffic livestreams. The dataset consists of 420 video clips captured from 17 distinct camera locations across Hanoi, totaling 8.83 hours of footage at 720p and 30 FPS.
- The original source material comprised continuous traffic livestreams accompanied by FM90 radio broadcasts. A dedicated data collection pipeline was developed to automatically segment the livestreams into clips, assign location-based metadata, and organize the resulting dataset, followed by manual quality control and verification. This process include:
- Building upon the video dataset, a uniform sampling strategy was applied to extract nearly 10,000 image frames for downstream analysis. In addition, 157 images from two selected camera locations were manually annotated to establish an initial ground-truth dataset for evaluation and experimentation.

Some notes regarding the dataset:
- 17 camera locations:
- 107 Le Hong Phong
- 119 Nguyen Hoang
- 45 Nguyen Luong Bang
- O Cho Dua
- Nguyen Van Cu
- 71 Nguyen Trai
- 1111 Giai Phong
- 216 Tran Duy Hung
- Ho Tung Mau
- Nguyen Hoang – Ton Vo Chi Cong
- Xa La
- 200 Nguyen Xien
- 66 Truong Chinh
- Nga Tu So
- Ton That Tung
- Quang Trung – Le Trong Tan
- Hong Ha
- The dataset is distributed as MP4 videos and PNG images.
- All footage was collected during morning hours under relatively favorable weather conditions, including overcast skies and mild sunlight.
- 720p at 30 FPS represents the highest quality available from the source HTV livestreams.
Several characteristics of Hanoi’s traffic environment became apparent during dataset collection and analysis.
- Motorcycles constitute the overwhelming majority of road users. At the available resolution, conventional bounding-box annotations become increasingly impractical for two-wheeled vehicles due to their small visual footprint, dense packing, and frequent occlusions.
- In many scenarios, motorcycles in Hanoi resemble people in crowd-counting problems more closely than vehicles in traditional object detection datasets. Rather than appearing as isolated objects, they often move as dense and highly interactive flows.
- The diversity of road users is remarkably high. Even within a single category such as buses, the dataset contains public buses, coaches, tourist buses, and other variants with substantially different sizes and visual characteristics.
- Beyond conventional vehicles, Hanoi’s traffic ecosystem also includes less common participants such as cargo tricycles, street vendors, and other informal road users that are rarely represented in existing traffic datasets.
4. Progress up until Midterm
At the beginning of the project, the HTVTraffic dataset had already been collected, but no annotations were available. To manage the scope of the work, the project was divided into two stages:
- Stage 1: Object Detection and Tracking
- Stage 2: Digital Twin Proof of Concept
For Stage 1, a perception pipeline was developed consisting of two models and two output streams.
- For “box-like” vehicles such as passenger cars, SUVs, buses, and trucks, a combination of YOLOv8 and SAHI was used to produce labeled 2D bounding boxes.
- For motorcycles and pedestrians, the problem was instead formulated as a crowd counting and localization task. Rather than producing labeled bounding boxes, the system outputs localization points representing the positions of traffic participants.
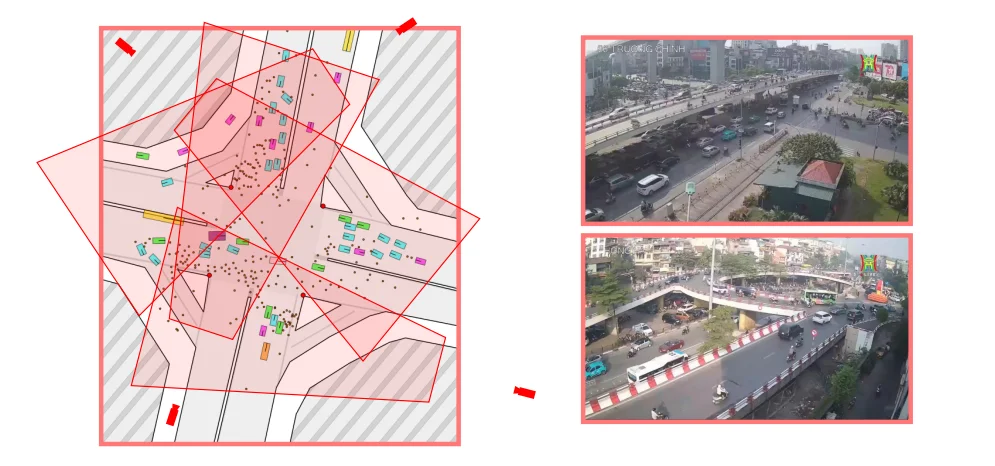
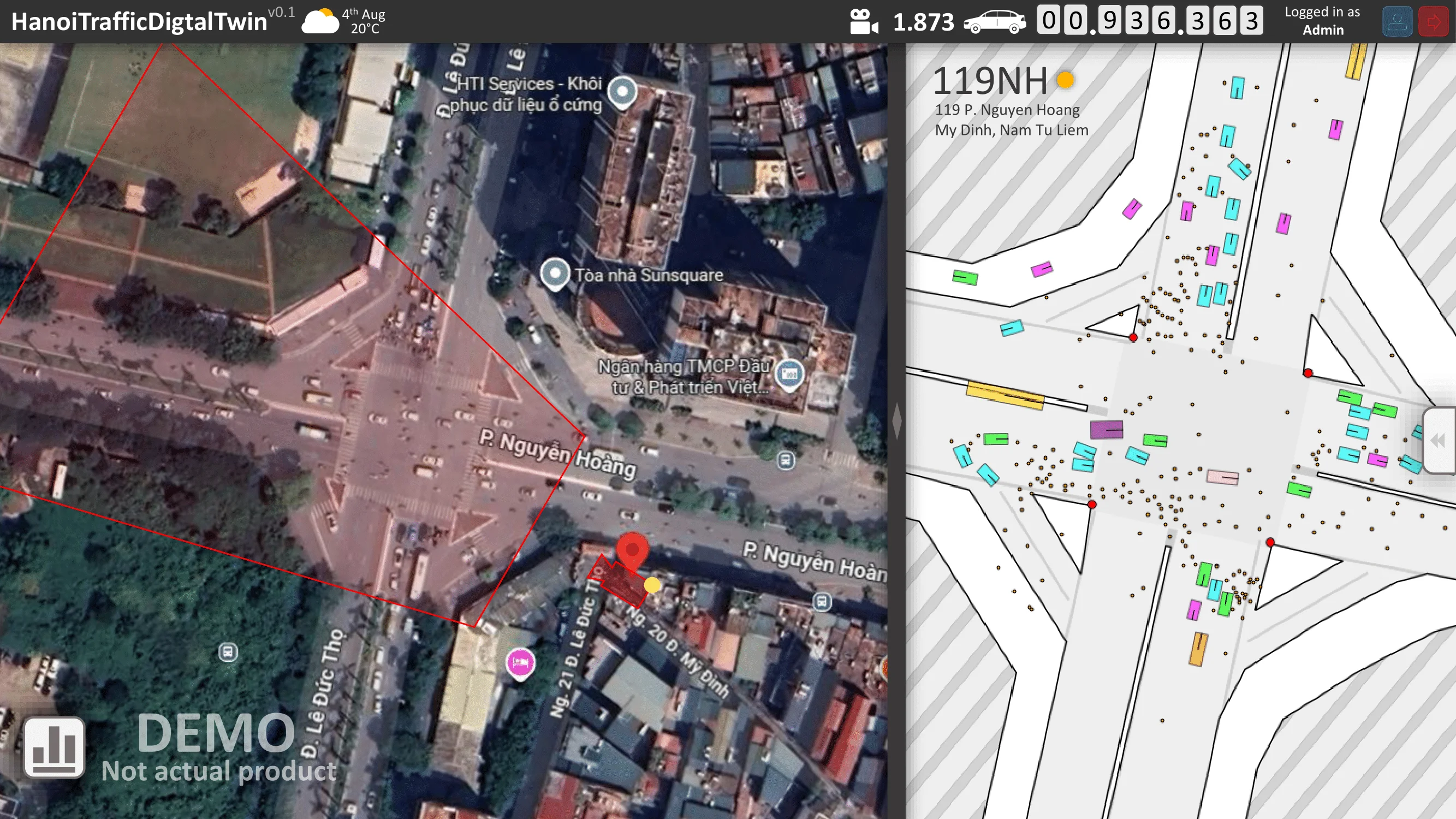
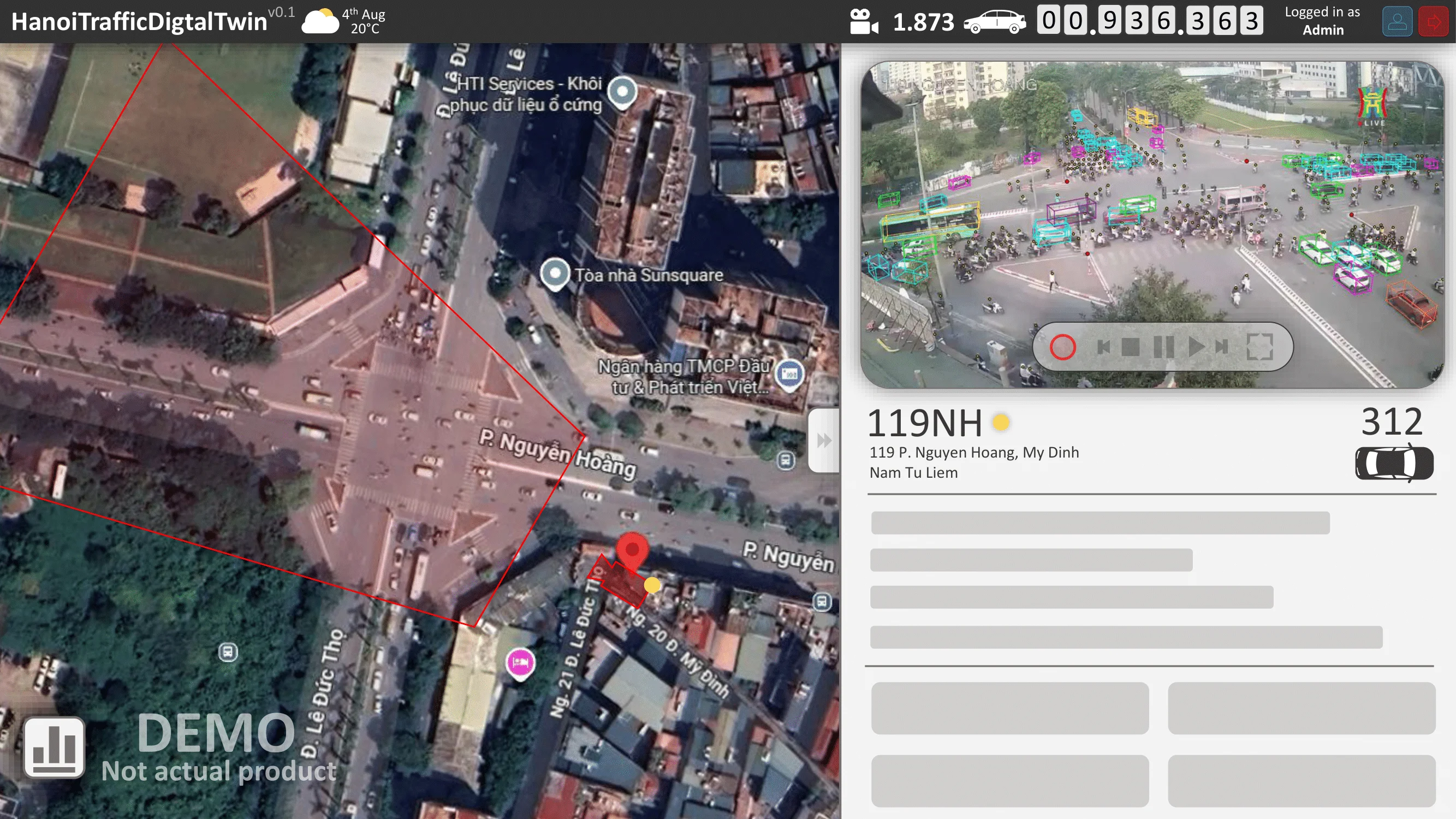
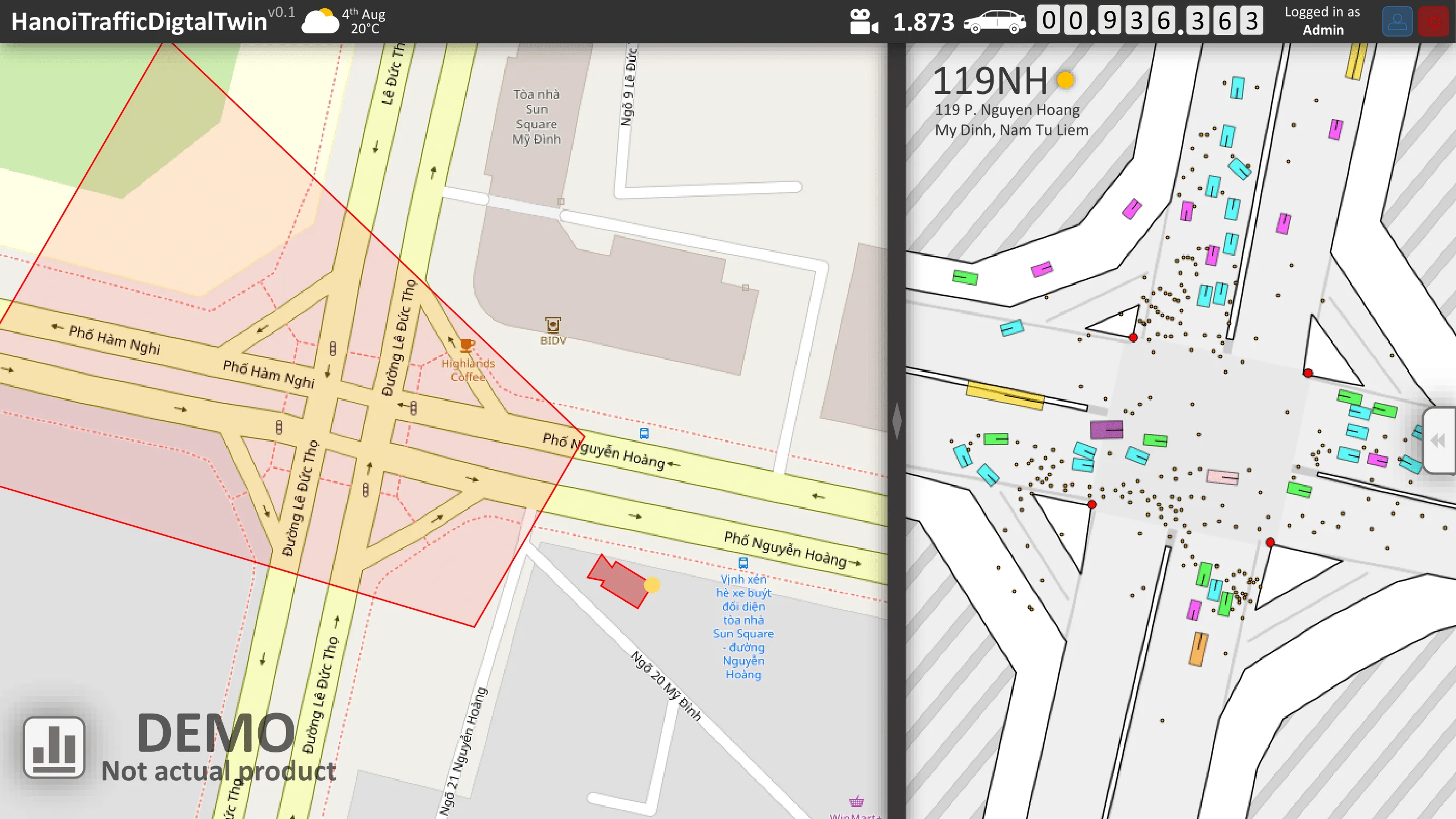
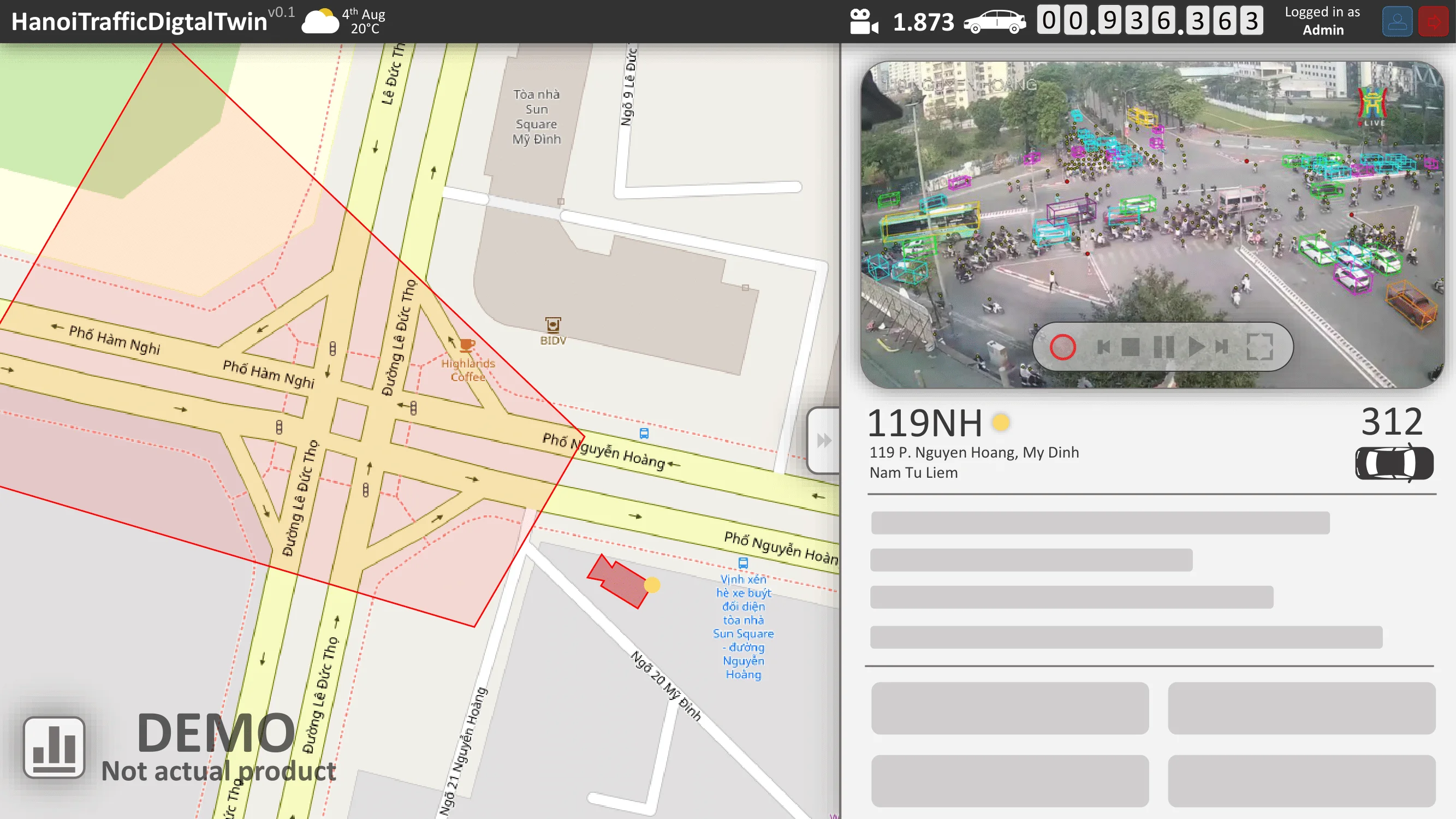
The desired result is a demonstration video. On the left, object detection and localization are performed in the CCTV domain. On the right, the detections are projected into the satellite domain using a geometric transformation $G$.
For Stage 2, a proof of concept Digital Twin was developed under the simplifying assumption that perfectly tracked objects with persistent IDs were available across frames.
Several key concepts were demonstrated:
-
The estimation of the transformation , enabling correspondence between CCTV imagery and satellite-space coordinates.
- The conversion of 2D detections into approximate 3D bounding boxes within the CCTV view.
- The integration of tracking and geometric projection into a simple Digital Twin visualization.
The resulting prototype demonstrates that, provided Stage 1 can achieve sufficiently reliable perception and tracking performance, the construction of a traffic Digital Twin is technically feasible. The remainder of the project focuses on investigating future improvements and establishing a roadmap for continued development through the end of the semester.
4.1. Phase 1: Detection and Tracking
4.1.1. Point quEry Transformer (PET)
The PET Model was introduced in Liu et al., 2023, which is a localized crowd counting model. Instead of outputting the classic density map for this kind of problem, it directly predicts both the probability and exact pixel of a point where there’s likely a human head. The mechanism of this model is very similar to the DETR models in the object detection task.
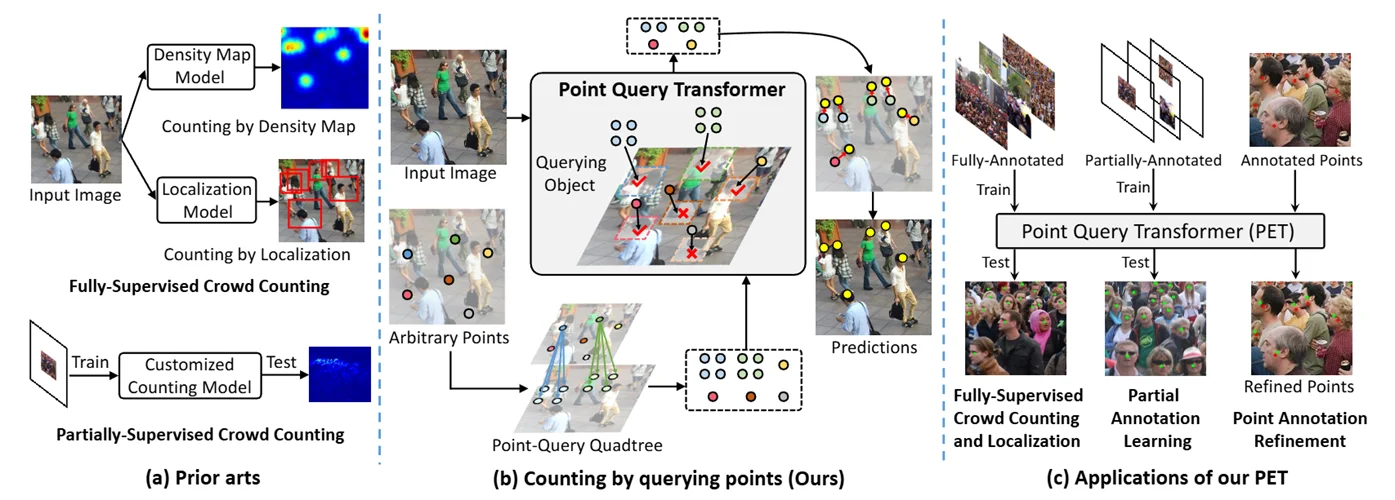
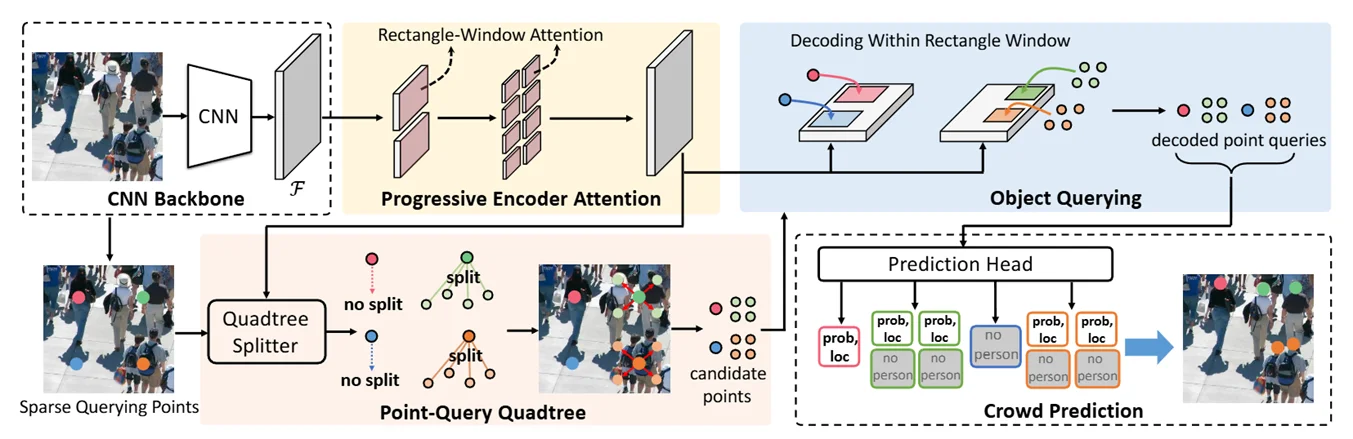
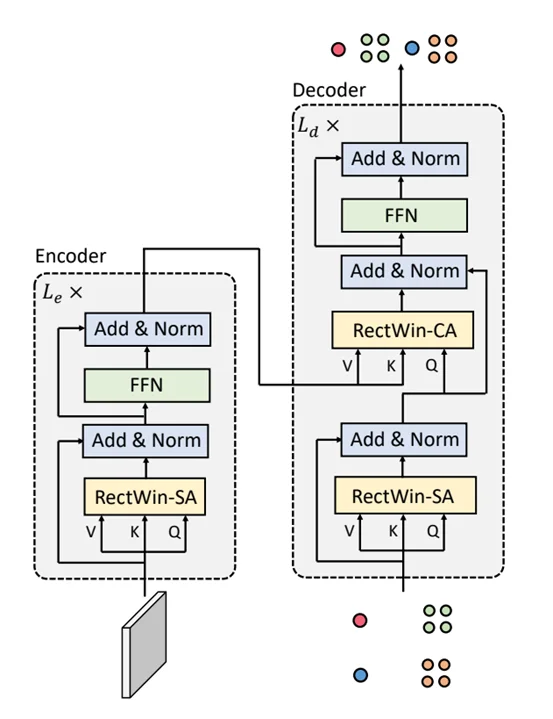
The model takes the feature map from a VGG16 backbone, apply self-attention to the Encoder at $\hat{x}^l$, sample query points on the feature map which is also the root of the quadtree. $\hat{x}^l$ is then evaluated along with the quadtree to see if a region needs to split into 4 more points for crowded areas.
The quadtree and $\hat{x}^l$ is then used as inputs for the decoder where cross-attention is applied to regress the point’s exact position in the original image space and their probability of there being a human head there.
Below are some prediction vs ground truth from a pretrained PET model:








Here, the images with the blue and red tint are predictions, the red tint rectangles are where the quadtree decided to split, ie. it thinks that region is “crowded”.
So quantitatively, I’d say its decent given the low quality of these images, as crowd counting from image task are usually done on high resolution images, however, thats still not good enough. So we move to the pain section of this process, trying to finetune this thing.
Originally, I also experimented with another model called P2PNet, it was fine but it was like an older CNN-based architecture, and its codebase quality and pretrained option was kinda insufficient, thus I focused on the PET model then.
So, lets just get right into my finetuning efforts for PET model:
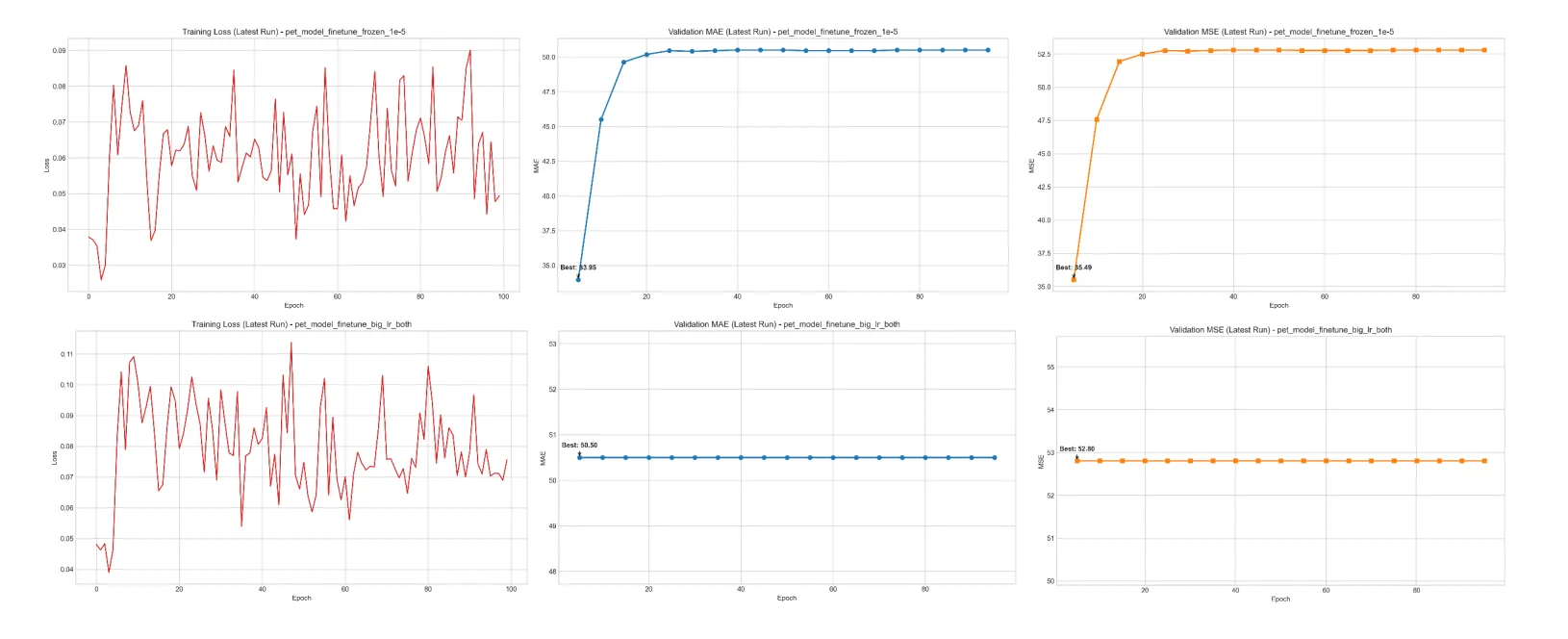
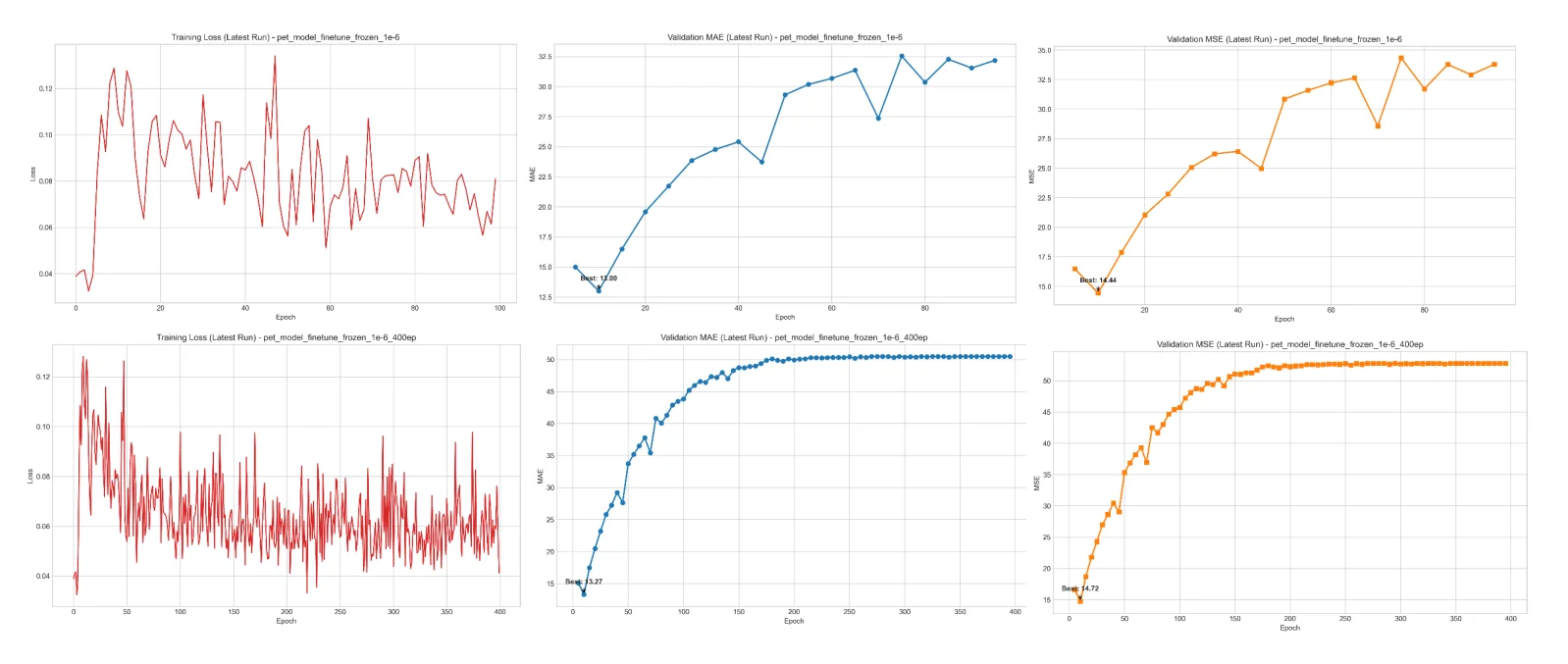
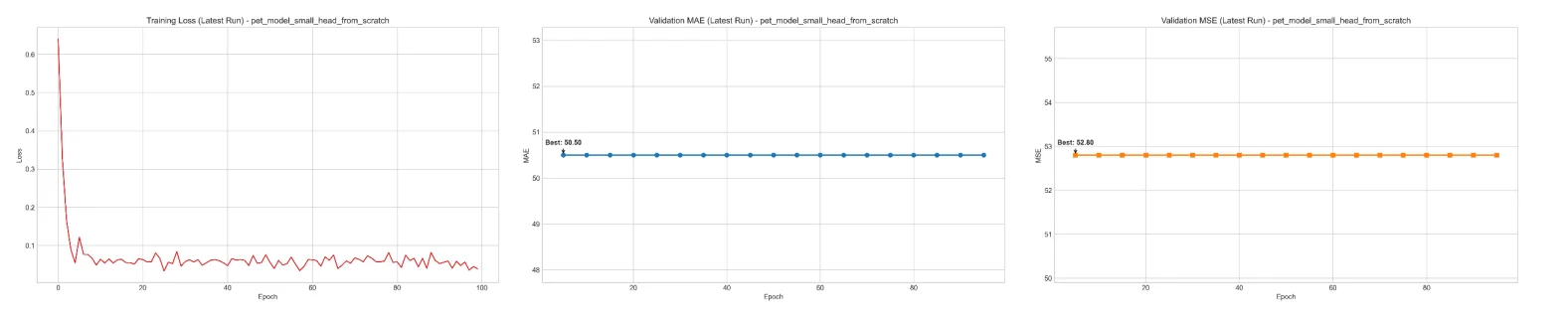
I’d say while the pretrained model performed decently, the finetuning was kind of a disaster. With just 115 annotated training samples from location code 107LHP, all attempts at finetuning lead to increasing error, diverging loss, or “model collapse” despite testing with various different arguments.
My main suspicions was:
- The data was simply insufficient to finetune a transformer like this
- Domain gap, the original PET model was pretrained on datasets like NWPU, which contain high resolution samples of pedestrian, while we are trying to get it to detect people on motorcycles which is the majority in these Hanoi scenes.
What more was that, compared to the Object Detection task’s community support, Crowd Counting was just not mature enough for me to put any more effort into this.
So yeah, honestly this crowd counting fiasco took a huge chunk out of my time on this project, while it was disappointing, I don’t think it was necessarily a waste, I learned a lot from it. Both on the technical side and the reality of “domain maturity”.
4.1.2. YOLOv8 and SAHI
Honestly theres nothing that interesting in this part, I just simply go over YOLOv8 and the SAHI paper, I kinda spent all my time on that crowd counting rabbit hole, so, moving on.
4.1.3. First Early Demo
Now this is the bread and butter of this early stage, an initial demo. I’m not gonna lie, only now do I see that this presentation slides order kinda don’t make sense, because I haven’t even introduced the projection and the concept of the actual final demo, I think what I wanted to do was like showcase the detection and tracking for both the boxes and points, but I didn’t want it to be dry or something lol, so I just included the full demo here anyway:
4.2. Phase 2: Digital Twin Proof of Concept
Yeah so honestly this I’m not really feeling like re-writing everything that has already been covered in TrafficLab 3D, but yeah basically this part I covered the G projection.
The only thing that is not in that post in this presentation is that I acknowledged the difficulty of trying to infer a 3D bounding box just from the 2D bounding box footprint, in TrafficLab 3D, I just use very naive fixed class-based prior-dimensions, which looks good enough, but I know I can do better, Im actively working on solving that problem so stay tuned!
But basically, I made an entire experiment to demonstrate the fact that the 3D bbox of a vehicle doesn’t always fit inside its 2D bbox:
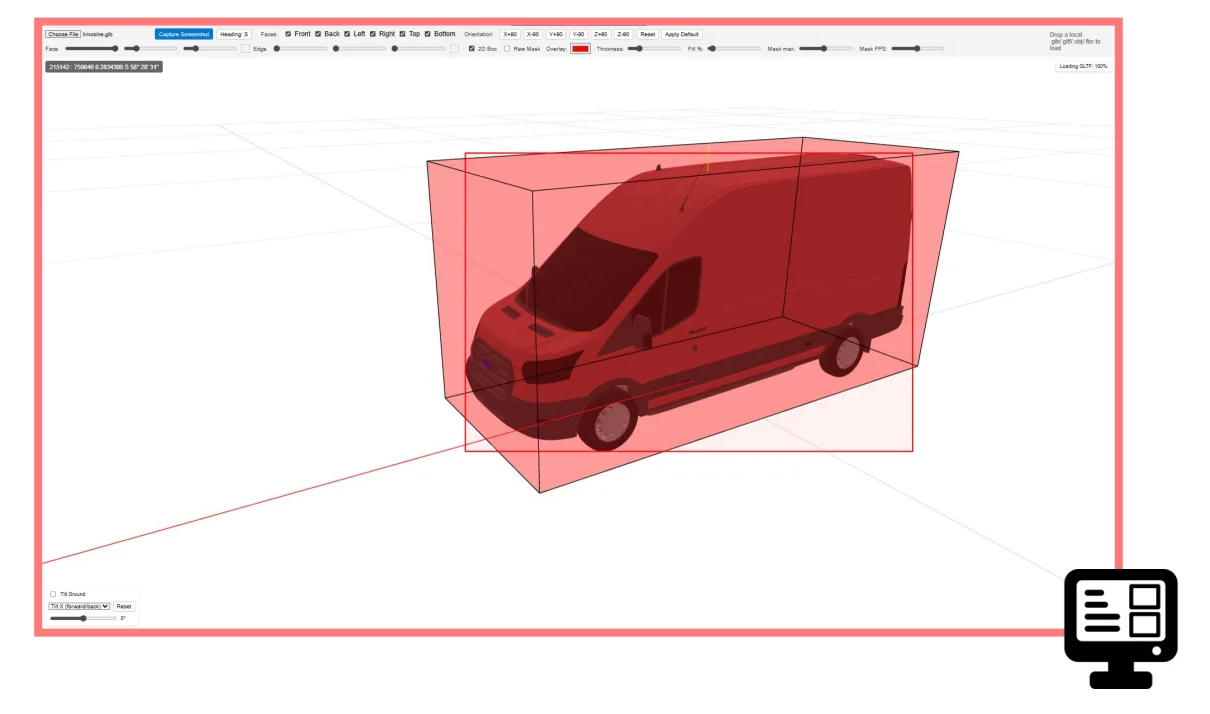
Later down the development cycle, this experiment helped me greatly in actually formalizing the center point and the final G projection in TrafficLab.
And the proof of concept here is the video in 4.1.3. First Early Demo lol.
5. So much stuff going on rn bru…
A bit of Yuk lore, I’ve been postponing this post for ages by now lol.
Yeah, I got a lot going on right now, but, just thought I shared this little snippet from my time with TrafficLab, It would have been easier to just copy paste the pptx file into this, but, oh well, its my blog.
Anyway, about TrafficLab 3D, so yeah this stuff was quite a while back, which is why im really lazy to actually make this post more formal because im pretty much mentally done with this phase y know? Already looking at whats next as I usually do.
But, I have ideas for TrafficLab, and im actively working and experimenting, I think im gonna push a new iteration of TrafficLab under a new name, this time, im thinking of making a collection of repos. I just don’t know when that vision will come out full and is up to my own standard, because, for now, its just me. The main goal is still to make accessible digital twins, of which I think traffic analysis is one of the more accessible modality as compared to like a warehouse or a natural site like beach shores, while also not being too much of a toy example, something fitting to encourage enthusiasts to get into this niche.
Originally this summer, I planned to pour all my effort into this next iteration of TrafficLab, but, some stuff come up recently, so, change of plan, in a good way I guess, but still, im definitely gonna continue on my personal stuff, would be even better if such work can align with a good paying job so I can actually fully focus on it. Afterall, if you love what you’re doing then its not even a job eh, well, im hopeful, until next time.
Here are some more interesting images from this early development phase: